记录机器学习基础知识、Pytorch基础使用。这次去年6月份的笔记了,当时开始转战AI了。
Pytorch
1. 基础

1.1 名词
特征
- 特征是数据中的各个属性或变量,它们用于描述数据的不同方面。在机器学习中,每个特征都是一个输入变量,可以是数值型、类别型、文本型等。
- 比如:对于一个房价预测模型,特征可能包括房屋面积、房间数量、地理位置等。
纬度
- 纬度是指数据集中特征的数量。每个特征代表一个维度。
- 比如:一个具有3个特征的数据集可以被视为在3维空间中,每个数据点都有3个坐标(即3个特征)。
纬度诅咒
特征向量很多的数据,会引发纬度诅咒。在高纬度空间中,会导致数据稀疏、计算复杂度增加、模型过拟合等。
例如,假设我们有1000个特征,数据在1000维空间中会非常稀疏,距离度量也变得不再有意义。
在高维空间中数据分析和建模面临的一系列问题和挑战。随着数据维度的增加,数据在高维空间中的稀疏性也增加,导致许多传统方法在高维空间中表现不佳。
根本问题:数据量(有特征的)少,导致在高纬空间稀疏性增加。
特征选择和降维
可以通过特征选择(去除不相关或冗余的特征)和降维技术(如主成分分析PCA)来降低纬度。
案例
数据集:鸢尾花数据集(Iris Dataset)
- 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
- 纬度:4(因为有4个特征)。
在这个数据集中,每朵花的数据点位于一个4维空间中。假设我们使用这些特征来训练一个分类模型来区分不同种类的鸢尾花:
- 如果我们引入更多特征(如花的颜色、花朵数量等),纬度将增加。
- 通过特征选择,我们可以选择对分类效果影响较大的特征来简化模型。
- 如果特征数量过多,可能需要使用降维技术来减少纬度,同时保留数据的主要信息。
向量和坐标
在向量空间中,每个数据点可以被表示为一个向量。
一个向量的每一个分量对应数据点的一个特征。例如:
1.2 人工智能系统的演变
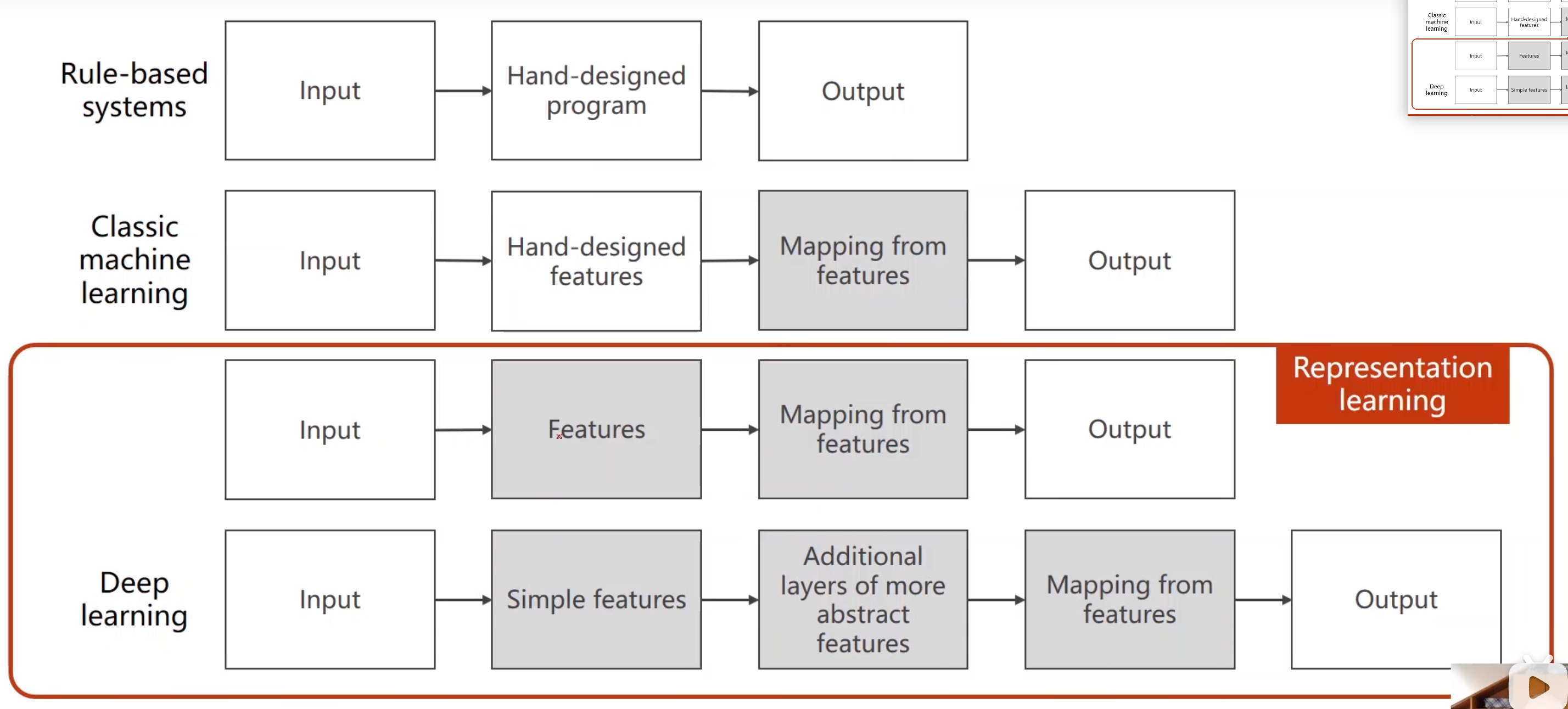
Rule-based systems(基于规则的系统):基于规则,手动设计多个规则,输入可以根据规则来输出。基于规则的系统是最早的人工智能方法之一,这种系统通过人工编写的规则来处理输入并生成输出。
工作流程:
- 输入:系统接收输入数据。
- 手工设计的程序:专家编写的规则程序处理输入。
- 输出:生成结果。
特点:
- 依赖专家知识:规则由领域专家编写。
- 缺乏适应性:难以应对复杂、多变的任务。
- 可解释性强:由于规则是手工编写的,系统的决策过程容易理解。
应用场景:
- 简单决策系统:如税务计算、简单的诊断系统。
Classic machine learning(经典机器学习):手动从输入中提取特征(最终变成一个向量 ),把输入和输出建立一个映射函数,f(x)=y的公式,最后输出经典机器学习方法通过使用预定义的特征和算法从数据中学习模型。
工作流程:
- 输入:系统接收输入数据。
- 手工设计的特征:专家从数据中提取重要特征(feature engineering)。
- 特征映射:使用机器学习算法(如线性回归、决策树等)对特征进行映射,从而生成输出。
- 输出:生成结果。
特点:
- 特征工程:特征的选择和设计对模型性能影响很大。
- 依赖领域知识:特征设计需要专家知识。
- 灵活性较强:可应用于各种类型的数据和任务。
应用场景:
- 图像识别、文本分类、预测分析等。
Representation learning(表示学习):把非结构化的输入,通过复杂的算法,提取出特征(向量)。然后根据映射函数得到输出。通过自动学习特征表示,将输入映射到输出。
输入:系统接收输入数据。
初始特征提取:从输入数据中提取初始特征,这些特征可能是手工设计的,也可能是从数据中自动学习得到的。
特征转换:通过不同的方法(如降维、聚类、编码等)将初始特征转换为新的特征表示。
特征映射:使用这些新的特征表示进行映射,生成输出。
输出:生成结果。
Depping Learning(深度学习):表征学习的一种实现方式,通过多层神经网络来学习数据的多层次表示,具有强大的特征提取和任务优化能力。
- 输入:系统接收输入数据。
- 简单特征:初始层提取简单特征。
- 更多抽象特征的附加层:通过多层神经网络提取 更加抽象和复杂的特征。
- 特征映射:最终使用这些抽象特征进行映射,生成输出。
- 输出:生成结果。
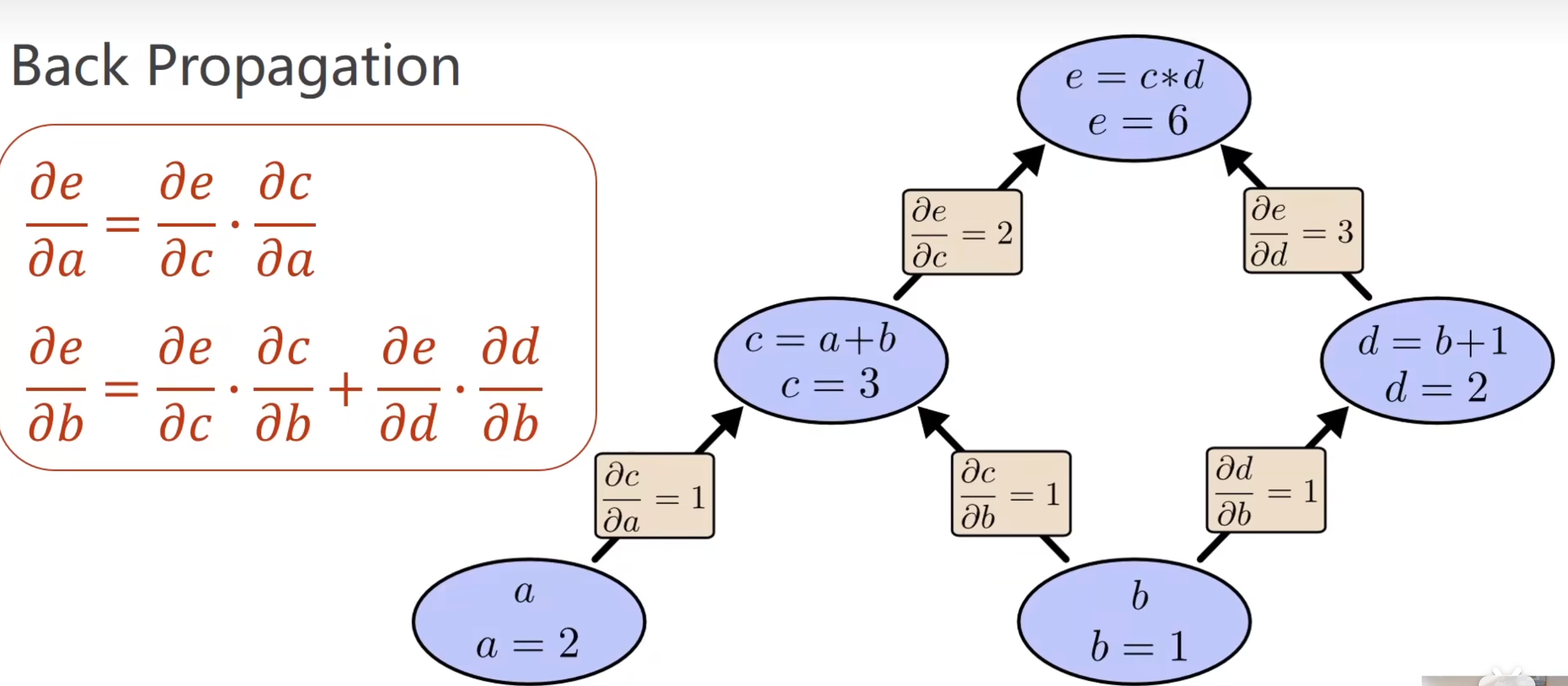
1.3 反向传播
实际上就是求偏导数
用计算图表示,每一步都是原子计算。
从下到上求e,是前推的过程。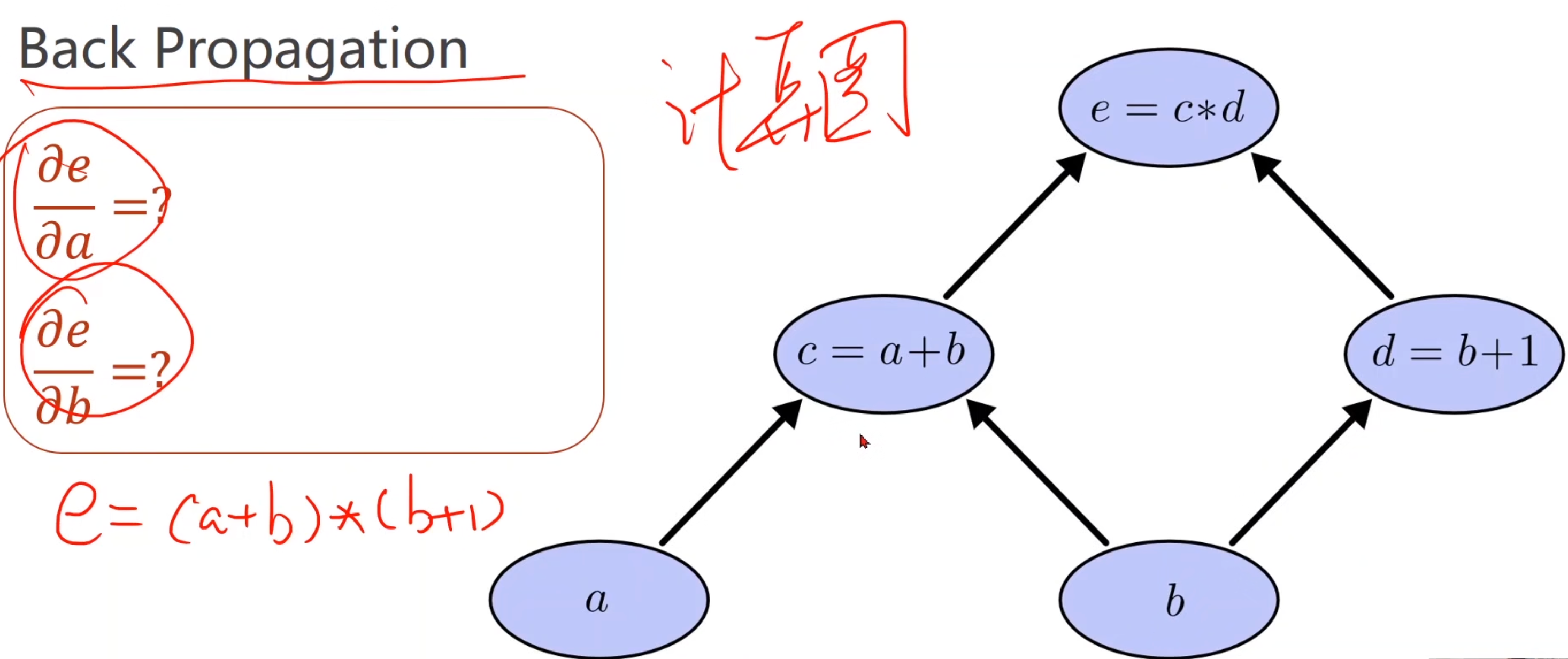
2. 线型模型
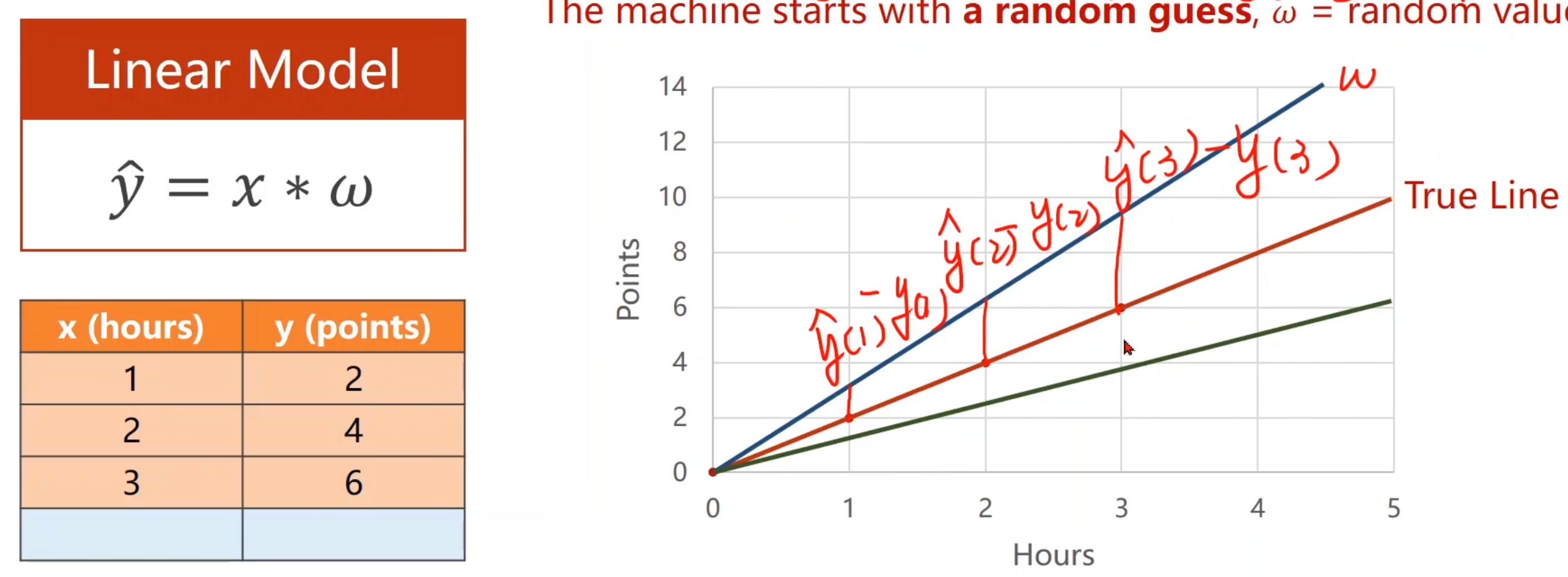
有一些数据集。
先用线性模型,y=wx+b。权重w。
随机一个权重,得到一个线型模型。
根据随机的线型模型,用输入获取输出y’。计算真实输出和y’的距离。
也就是说,通过某个方法找到当前模型和真实数据之间的误差。 也就是
Loss
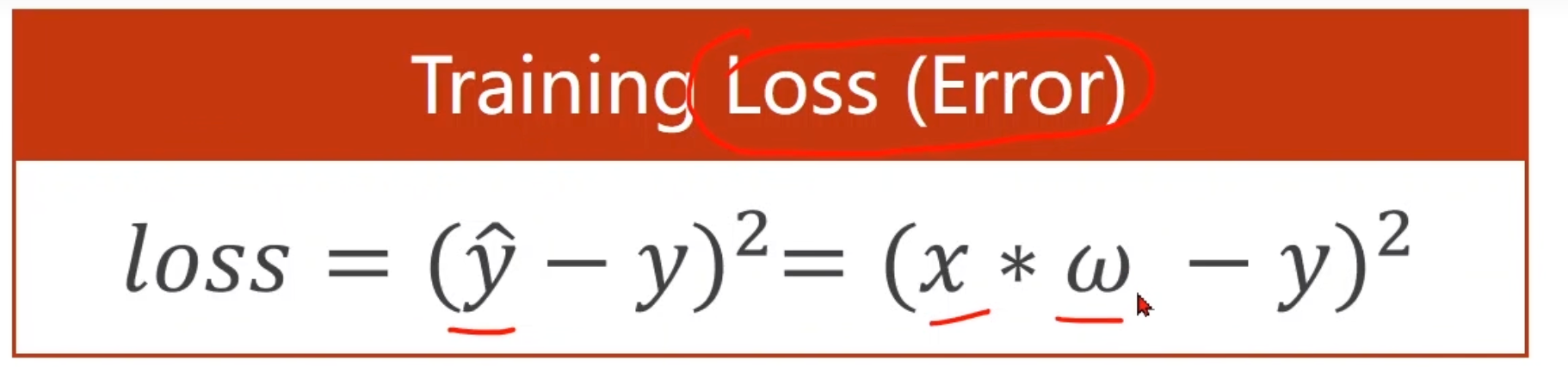
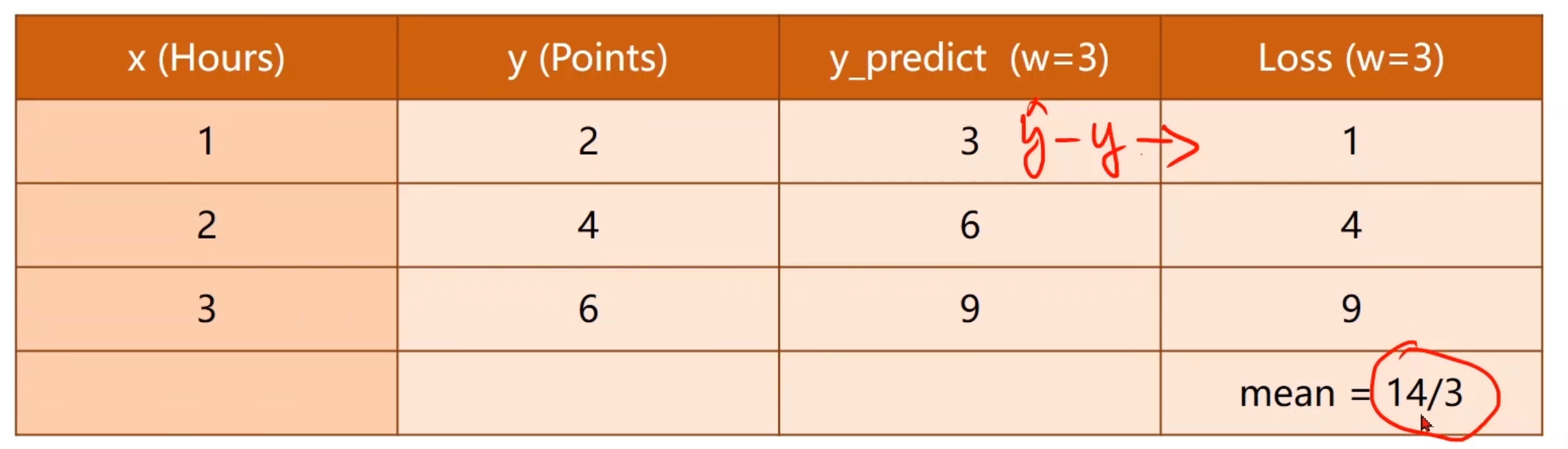
计算均方差 。w=3时
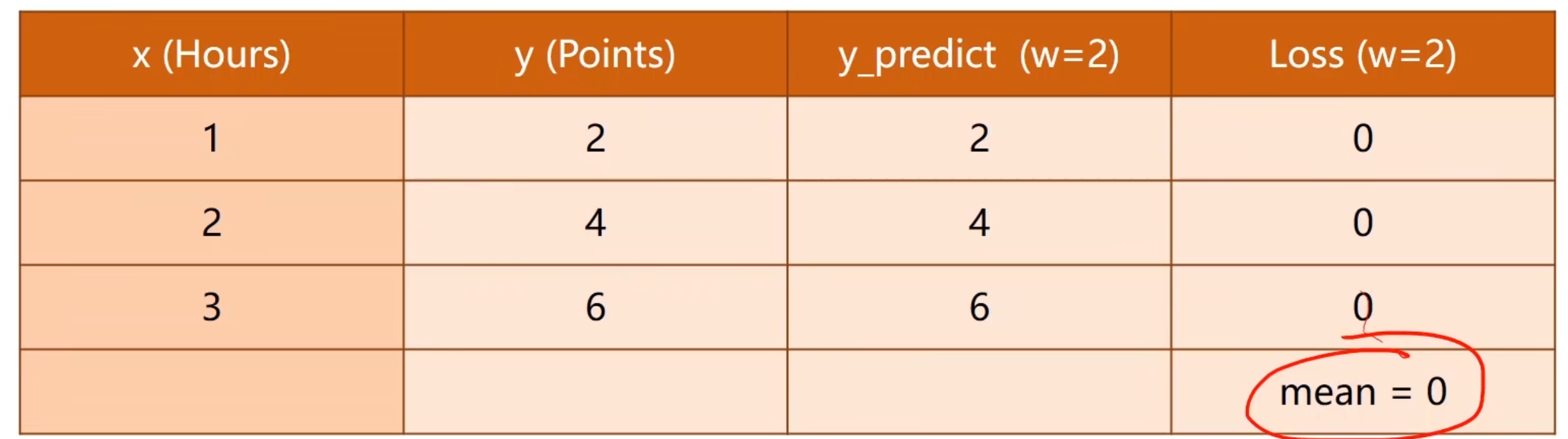
w=2时。
注意:
对所有的样本:平均平方误差:
Mean Sequare Error(**MSE**)


2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import matplotlib.pyplot as plt
# 数据样本
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 线型模型
def forward(x):
return x * w
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
# 预测的权重w,作为图的x轴
w_list = []
# 每个权重w对应的损失值,作为图的y轴
mse_list = []
# 在某个范围内,穷举权重w
for w in np.arange(0.0, 4.1, 0.1):
print('w=', w)
l_sum = 0
# 遍历每个样本,计算损失值
for x_val, y_val in zip(x_data, y_data):
# 预测值
y_pred_val = forward(x_val)
# 损失值
loss_val = loss(x_val, y_val)
# 累加损失值
l_sum += loss_val
print(f"\t{x_val} {y_val} {y_pred_val} {loss_val}")
# 三个样本的平均损失值
print(f"MSE = {l_sum / 3}")
w_list.append(w)
mse_list.append(l_sum / 3)
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()加上常数:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [3.0, 5.0, 7.0]
def forward(x):
return x * w + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
w_list = []
b_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
for b in np.arange(0.0, 4.1, 0.1):
print('w', w, 'b', b)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum / 3)
w_list.append(w)
b_list.append(b)
mse_list.append((l_sum) / 3)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 绘制线框图
ax.plot(w_list, b_list, mse_list, 'o-')
print(w_list)
# 设置标签
ax.set_xlabel('w')
ax.set_ylabel('b')
ax.set_zlabel('Loss')
# 显示图形
plt.show()
3. 梯度下降
3.1 意义
从线型模型,大概了解到了数据集、模型、Loss之间的关系。
那么模型的权重w,怎么快速求得,是一个问题。根本问题:如何最小化损失函数
假设Loss是光滑凹凸曲线,在这个曲线上,对某个w求偏导,可以知道当前w的方向。(导数>0,增函数;导数<0,减函数),那么沿着这个方向不断的测试w,可以得到最小Loss的w。(理想状态下)
事实上,Loss曲线是不光滑的非凸函数,只能找到局部最优。
- cost(cost function,损失函数)
- 学习率:相当于w移动的距离
- 每次迭代,都向着下降最快的方向走,典型的贪心。这是局部最优结果
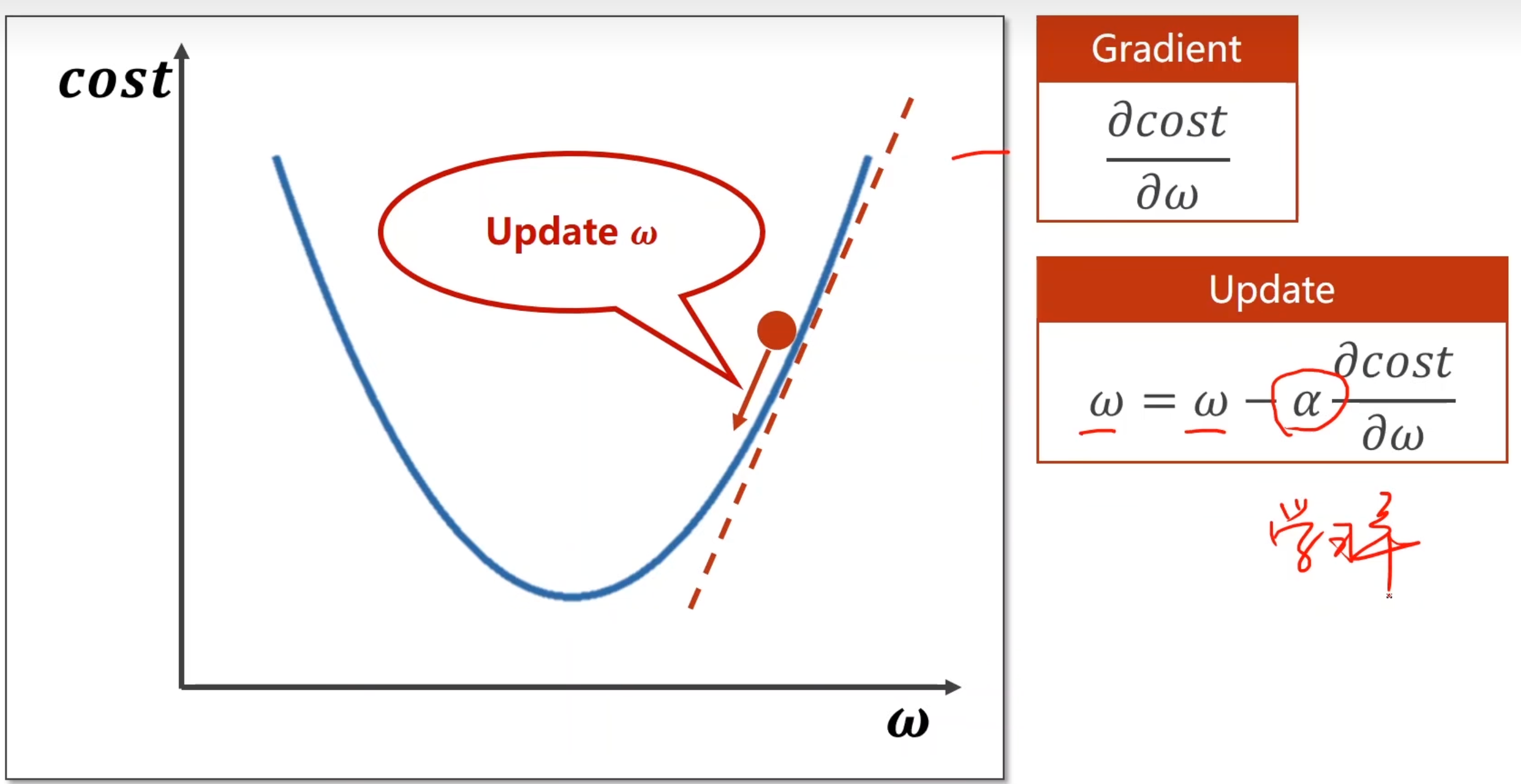
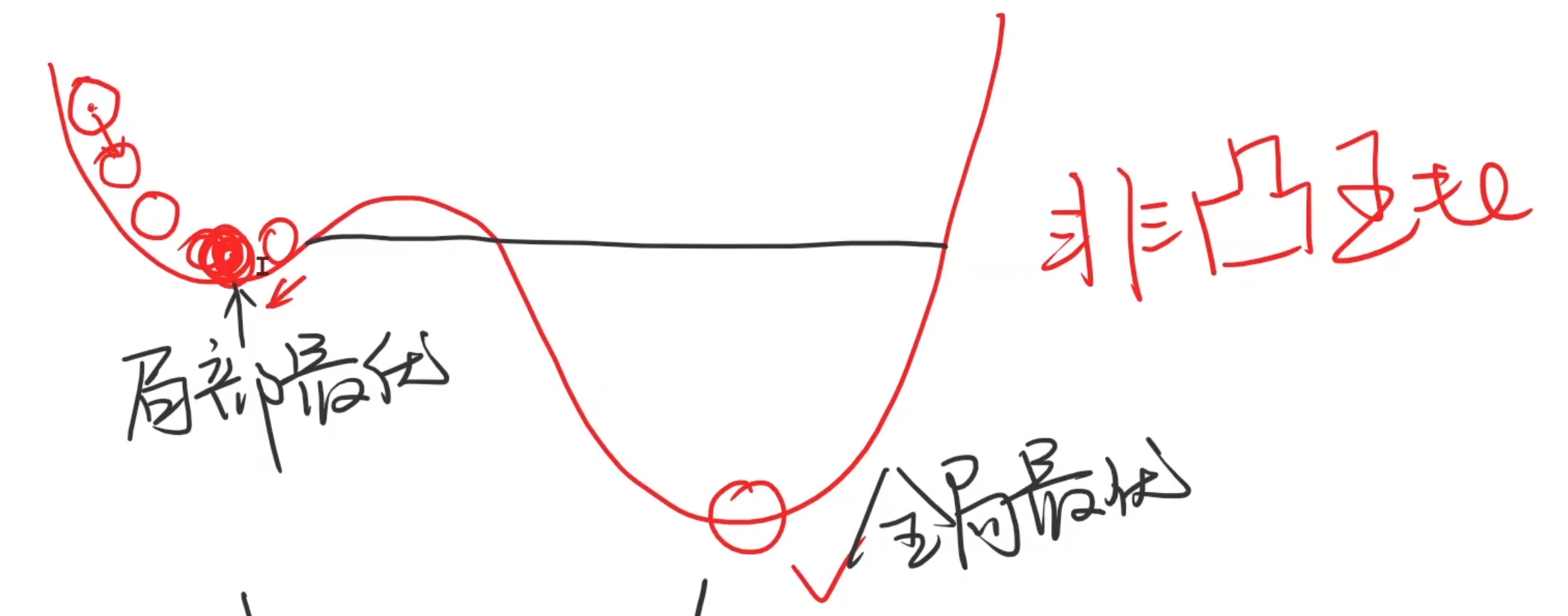
- 鞍点:不能继续迭代的点(梯度是0 ,走不动了),在一个水平线 或 从一个面上看是最低从另一个面看最高
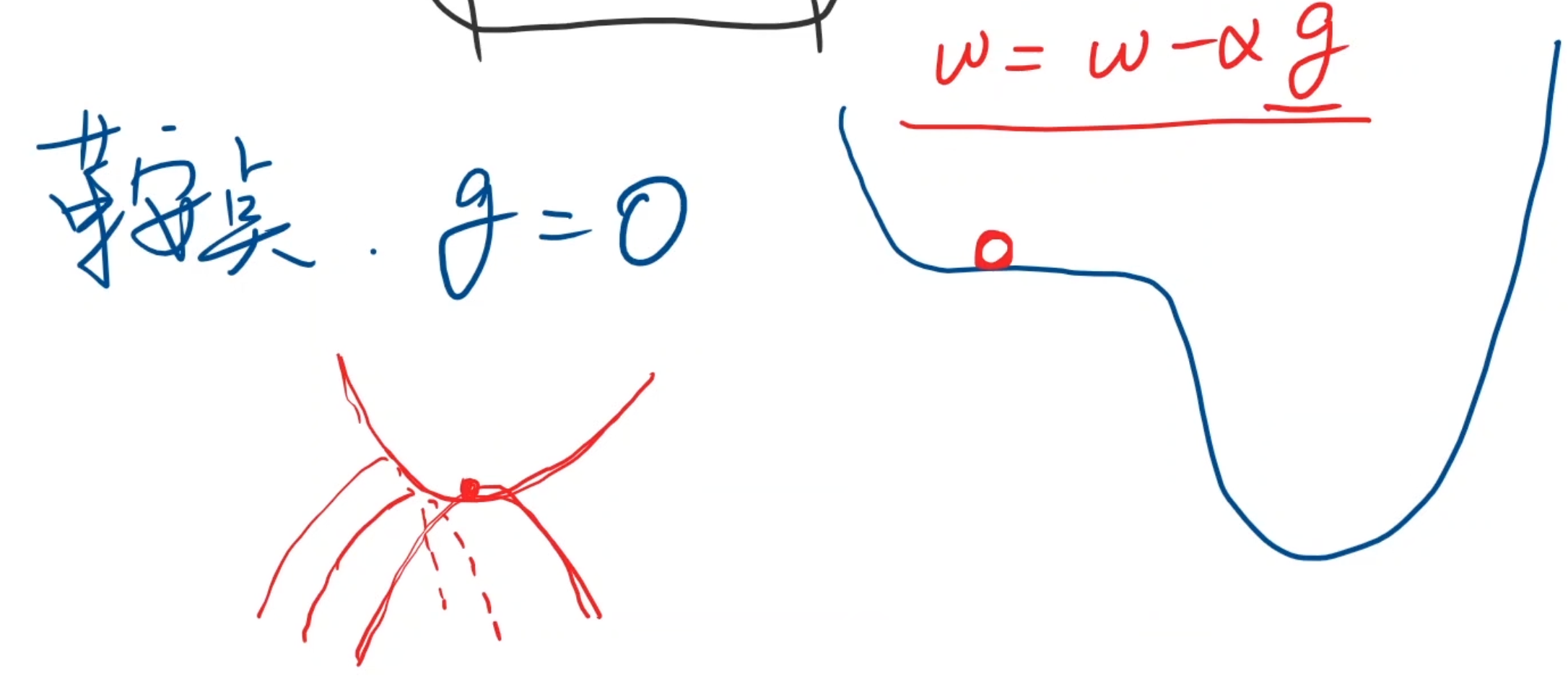
3.2 公式

1 | import numpy as np |
3.3 随机梯度下降 Stochastic
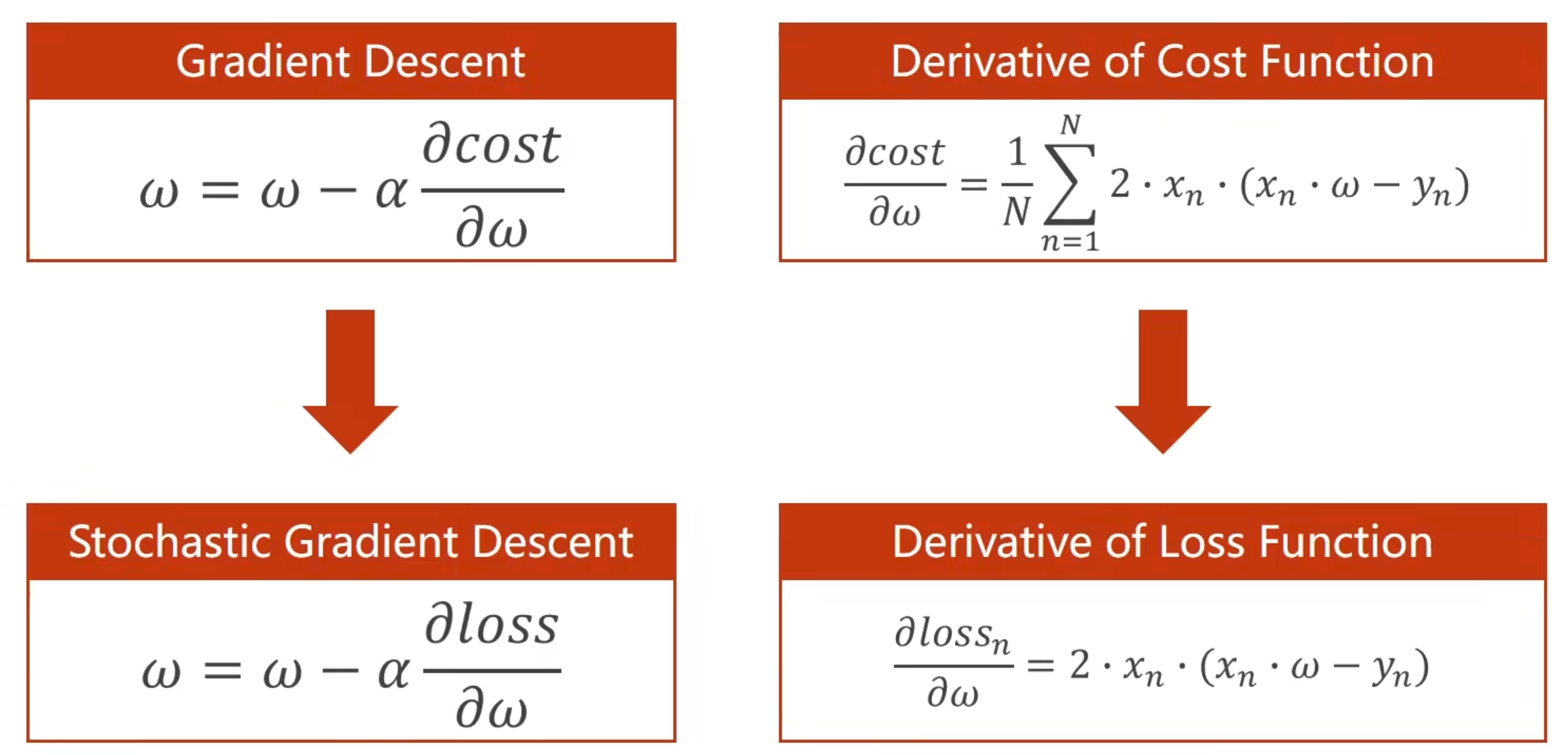
- 梯度下降:cost,用平均损失作为梯度下降更新的依据。比如N个样本,就需要计算N样本的损失
- 随机梯度下降:从N个样本中随机选一个,就成了拿单个样本的损失作为梯度下降的更新依据。
随机梯度下降的好处
加入在鞍点的情况下。使用cost会停止不同。但是如果只用一个样本,样本都是有噪声的,也就有了一个随机噪声,这个噪声可能就会帮助向前推动,有可能就会跳过鞍点,找到最优值
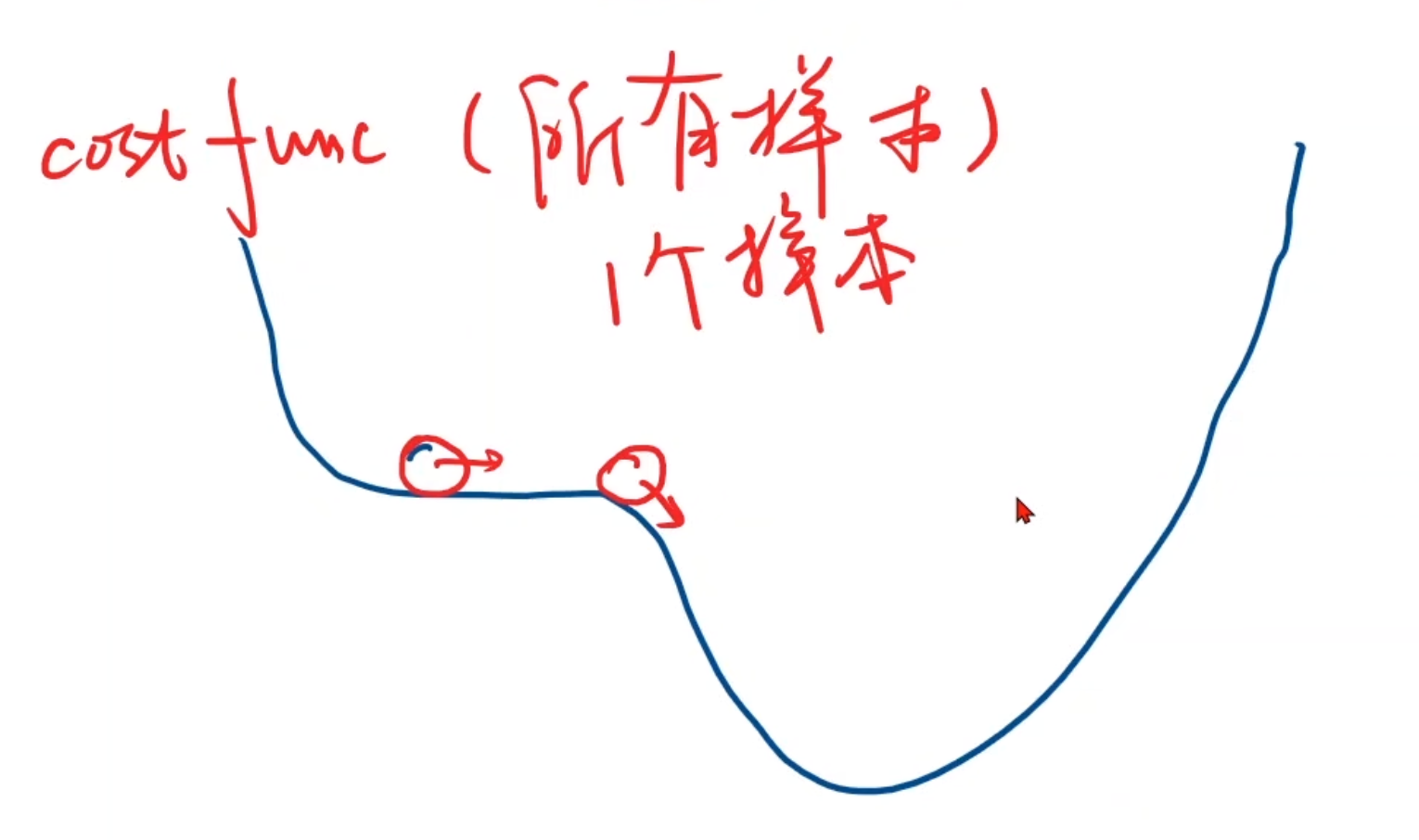
全部样本都计算损失(样本独立算损失,不是想之前那个求平均)
1 | import numpy as np |
存在的问题:
- 梯度下降:cost一次计算时,样本之间的损失没有关联(最后是损失的和),可以并行计算。
- 随机梯度下降:样本之间的损失是有关系的,因为当前样本计算的权重w,依赖上一个样本的w。这时的计算是不能并行的
梯度下降:效率高、性能低
随机梯度下降:效率低、性能高(比梯度下降拿到的最优值更好)
3.4 Mini-Batch
小批量梯度下降
一种常用的梯度下降优化算法,它结合了批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent, SGD)的优点,提供了一种在速度和稳定性之间折中的方法。
每次不对全部的N个点求损失的均值,而对某些点M(M<N)
注意:这里老师【刘二大人】和其他博主讲的是相反,其他博主是说梯度下降(即批量梯度下降)效率最慢,结果好。随机梯度下降是从N个点中选择一个点,效率最好,结果差(实际上刘二老师也说的是选一个,但是代码中,实际上还是都选了。。)。
这里等之后有时间或其他机会,再研究。
5. 反向传播
拿之前线性方程的举例。现在的
X是N纬矩阵,W是M✖️N纬矩阵,H=W*X,是M纬矩阵。H就是中间结果(隐藏层),H也是下一层的输入X’,再下一层H’=W’ * X’,最后得到loss。这是一个前推的过程
得到loss之后,就需要求梯度、更新参数。
最终需要求的梯度是:loss对w对偏导(对于中间产生的H即X’, 也需要求loss对X’的偏导,因为他是中间结果,他的上一层,需要这个结果)
loss对W对偏导,可以链式拆分:loss对H的偏导*H对W对偏导。
就这样逐层计算。当前层的链式计算表达式,其中可以用到后一层的结果,这是反向传播的过程

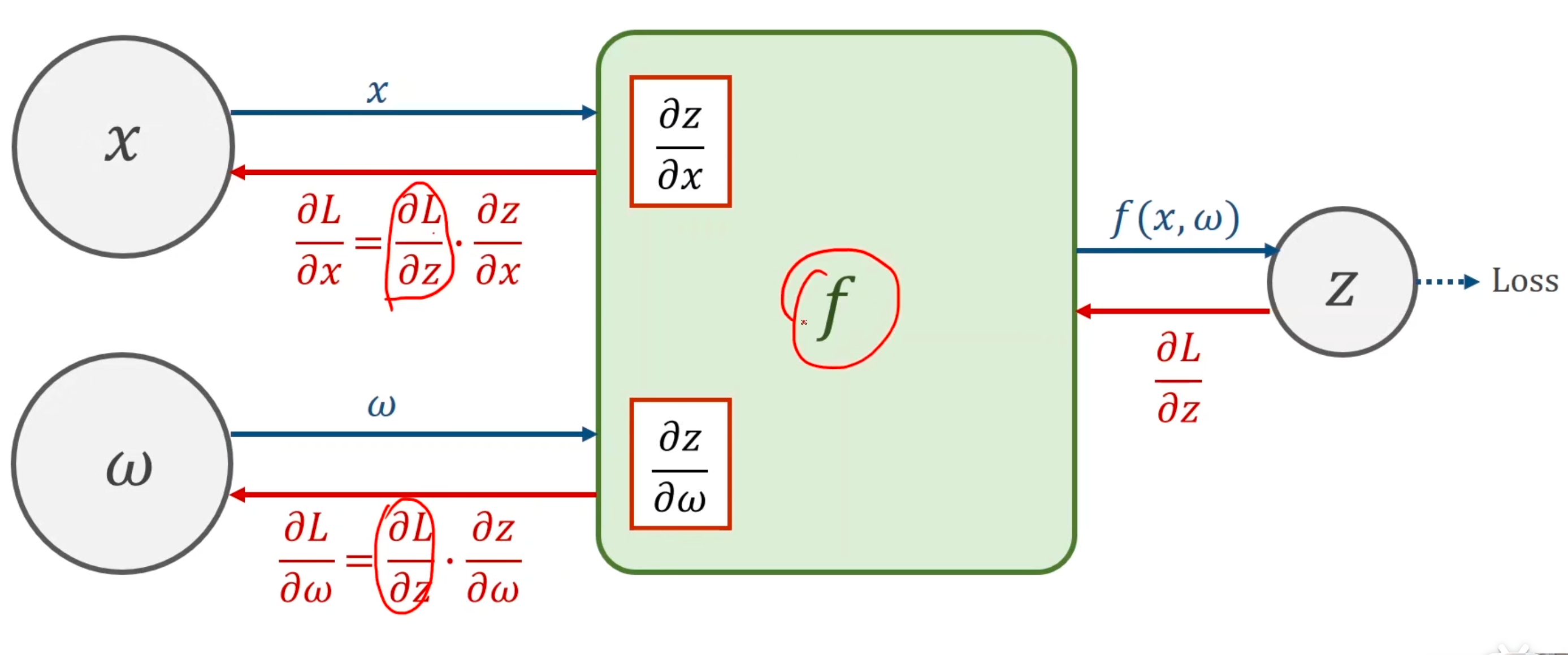
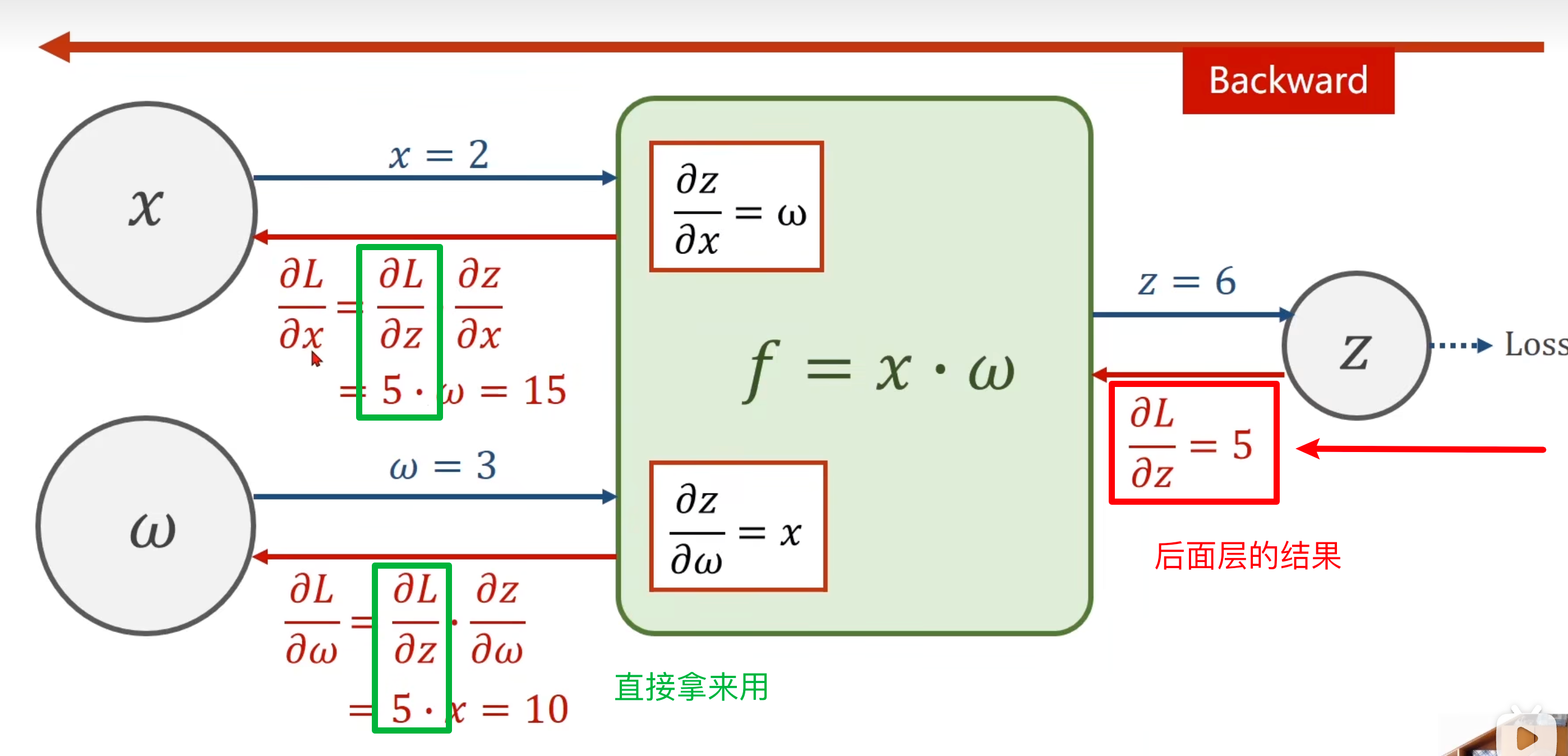
解决了下面的问题:
梯度计算:
- 问题: 神经网络中包含多个隐藏层,每一层都有大量的参数(权重和偏置)。要调整这些参数使得网络的输出与期望输出尽可能接近,需要计算损失函数关于每个参数的梯度。参数x是一个N纬矩阵,如果按照一纬线型的方式求loss、梯度下降,那么计算量很庞大。
- 解决: 反向传播算法使用链式法则(链式求导法则)来高效地计算损失函数关于每个参数的梯度。这些梯度用于更新参数,使得损失函数的值在训练过程中逐渐减小。
权重更新:
- 问题: 一旦计算了梯度,需要使用这些梯度来更新网络中的权重,以减少预测误差。
效率问题:
- 问题: 直接计算每个参数的梯度在深度神经网络中可能会非常耗时且复杂,特别是当网络层数较多时。
- 解决: 反向传播通过逐层计算梯度,利用前向传播时保存的中间结果,可以有效地减少计算量。具体来说,通过逐层计算误差的传播,从输出层到输入层反向传播误差,使得梯度计算更加高效。
反向传播的核心步骤
- 前向传播:
- 输入数据通过网络,从输入层经过各个隐藏层,到达输出层,计算出网络的预测值。
- 损失计算:
- 根据网络的预测值和真实值,计算损失函数值。
- 反向传播:
- 从输出层开始,逐层计算损失函数关于每个参数的梯度,反向传播到输入层。
- 权重更新:
- 使用梯度和优化算法(如梯度下降),更新每个参数的值。
前向传播目的是计算损失,反向传播目的是计算梯度来更新参数。
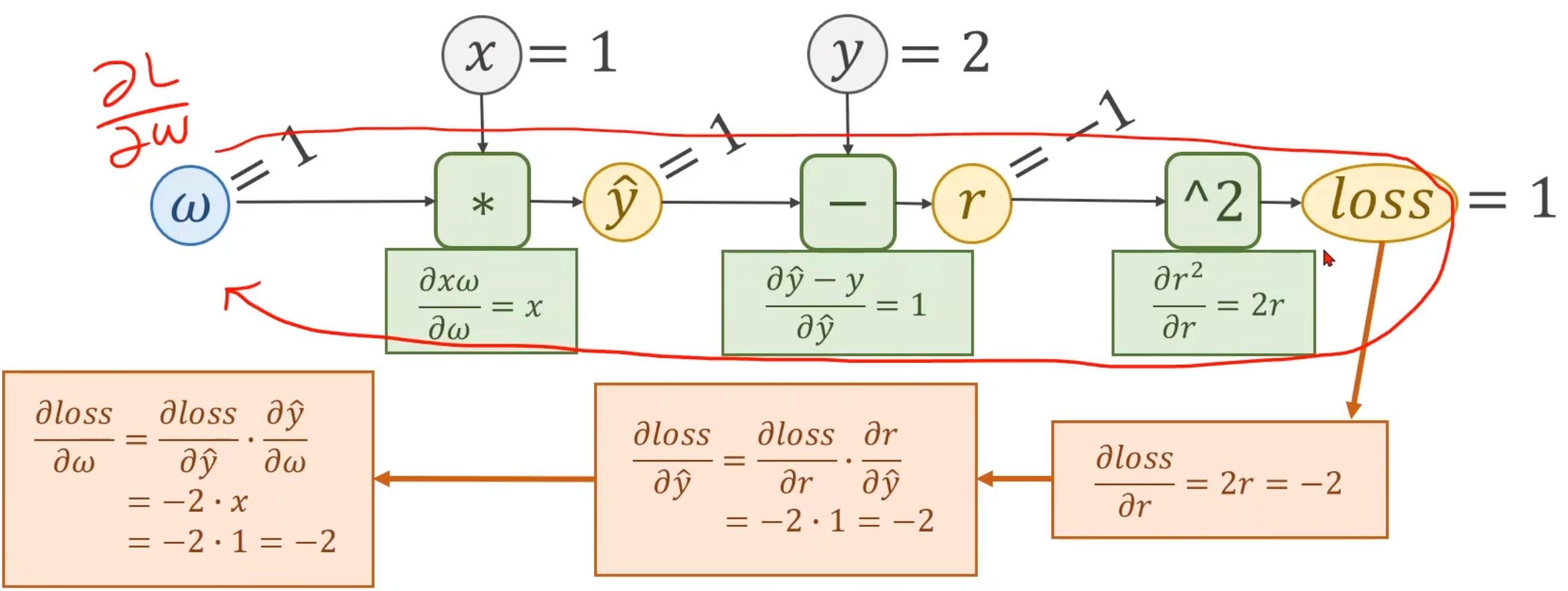
5. Pytorch
Pytorch基础:
- Tensor存放数据,可以是标量、向量、矩阵、高阶矩阵。就说任何类似的数值都行
- w是Tensor(张量类型),Tensor中包含data和grad,data和grad也是Tensor。grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用
w.grad.data- 如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
2
3
4
5
6
7
8
9
10
11
12
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
a = torch.tensor([1.0])
a.requires_grad = True # 或者 a.requires_grad_()
print(a)
print(a.data)
print(a.type()) # a的类型是tensor
print(a.data.type()) # a.data的类型是tensor
print(a.grad)
print(type(a.grad))
- 反向传播主要体现在,
l.backward()。调用该方法后w.grad由None更新为Tensor类型,且w.grad.data的值用于后续w.data的更新。- l.backward()会把计算图中所有需要梯度(grad)的地方都会求出来,然后把梯度都存在对应的待求的参数中,最终计算图被释放。
- 取tensor中的data是不会构建计算图的。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import matplotlib.pyplot as plt
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([0.1])
# 需要计算梯度
w.requires_grad = True
# 注意这里的w是一个tensor,所以x也要是一个tensor(如果不是,那么会自动转换类型)
# 并且,这不是一个乘法,而代表一个计算图
def forward(x):
return x * w
# 这也是一个计算图
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
l_list = []
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
# 反向传播。backward自动根据计算图,把所有需要梯度的地方都求出来。梯度会存到w中
# 执行完毕,计算图会被释放。下次loss会创建一个新的计算图。
l.backward()
print('\tgrad:', x, y, w.grad.item())
# 这里我们需要的是值,所以用data。如果用w,那么会得到一个tensor,而不是一个值
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
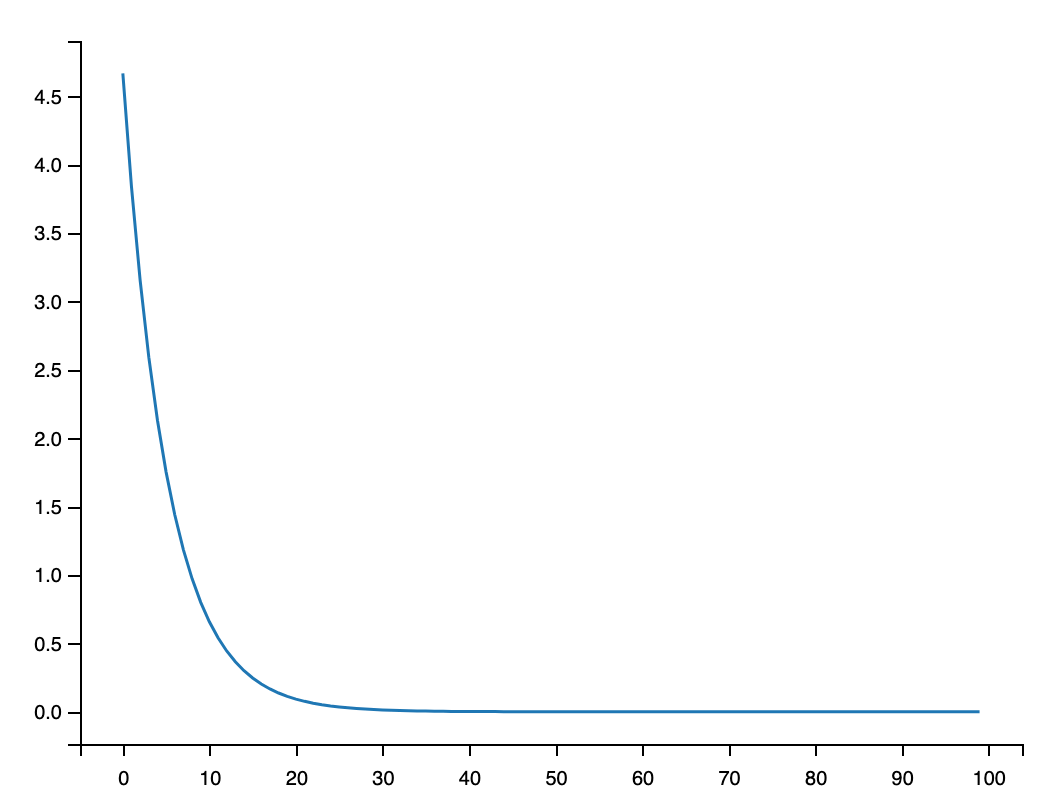
print("Epoch: ", epoch, "w=", w, "loss=", l.data)
l_list.append(l.data)
# 因为每个样本都做了一次,所以是100*3
plt.plot(range(100), l_list)
plt.show()
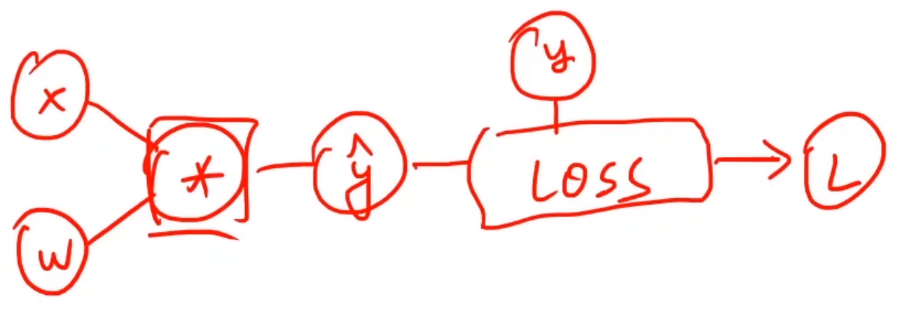
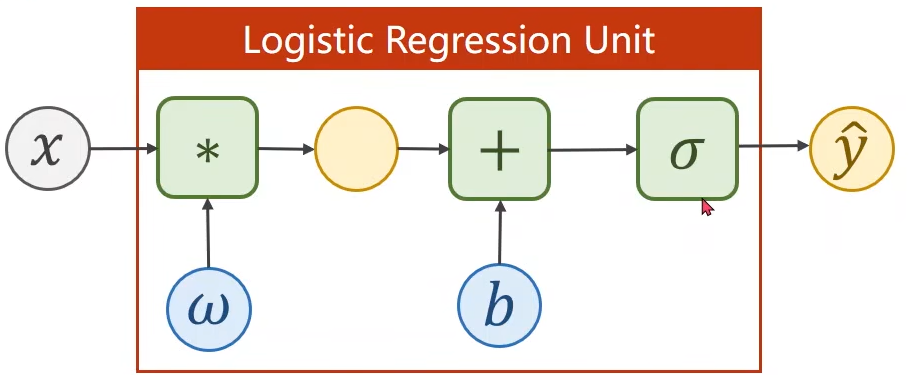
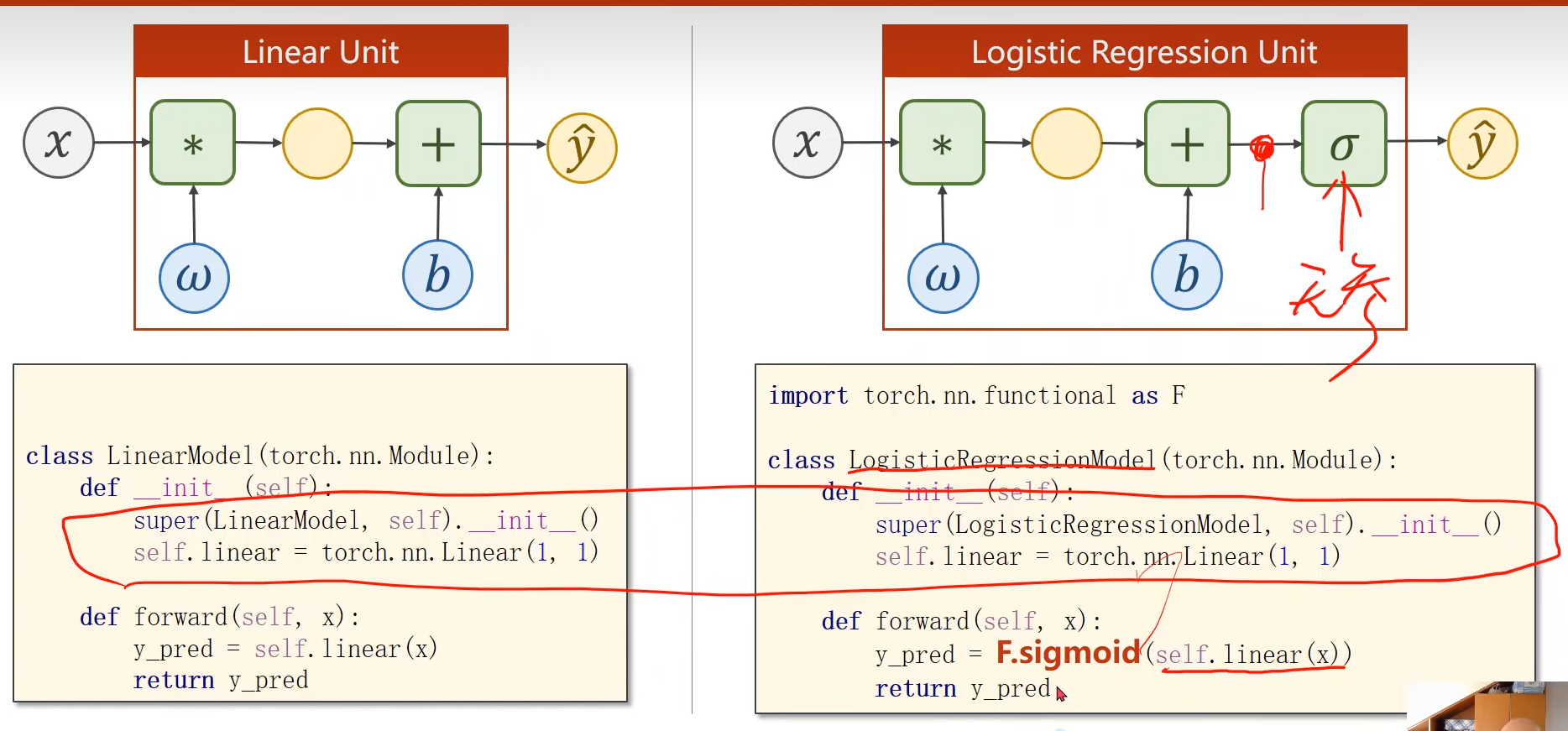
6. 逻辑斯蒂回归
6.1 二分类问题与sigmoid函数
二分类问题:假如手写字体识别的例子,判断数字是0-9的概率。实际上求的是P(y)=1的概率(即手写数字是某个数字的概率)。
由于我们求的是概率,那么我们的输出值,需要限定在[0,1]区间。
使用下面这个函数,将结果带入
这种函数被称为:sigmoid函数
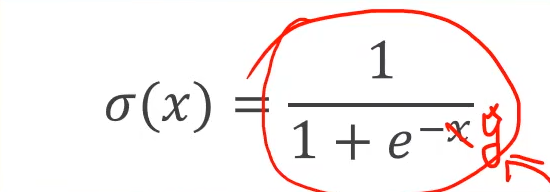
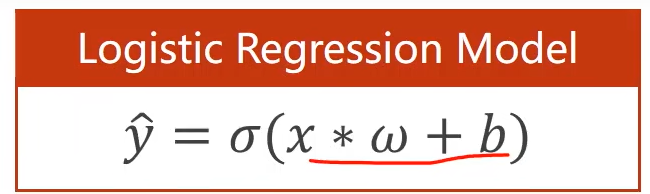
6.2 损失函数和交叉熵
前言:在线程回归中,我们计算损失是求y‘和y的距离,这是几何意义。但是在概率上就不能这样了,要计算的是两个概率分布的差距。
例如:
有两个分布D、T,用下面的公式可以计算两个分布之间的差距,越 大 越好
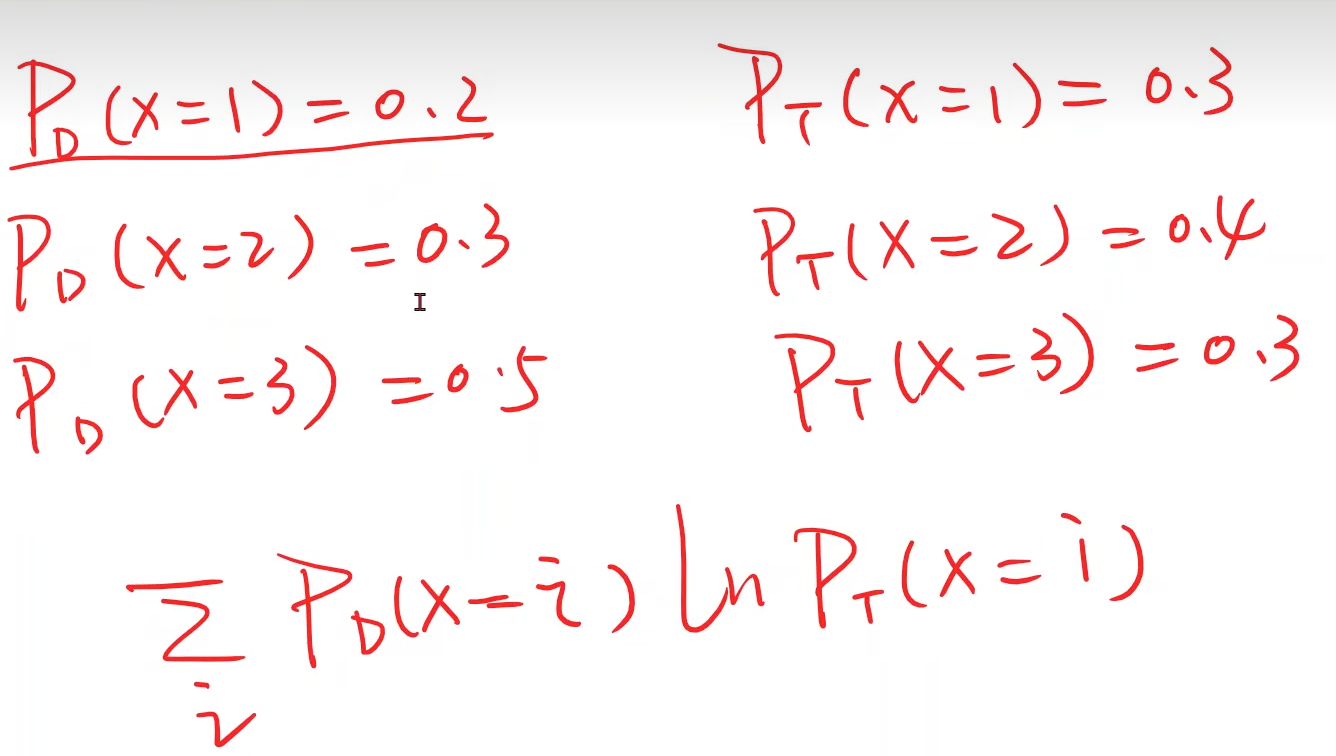
加负号之后就成了越小越好

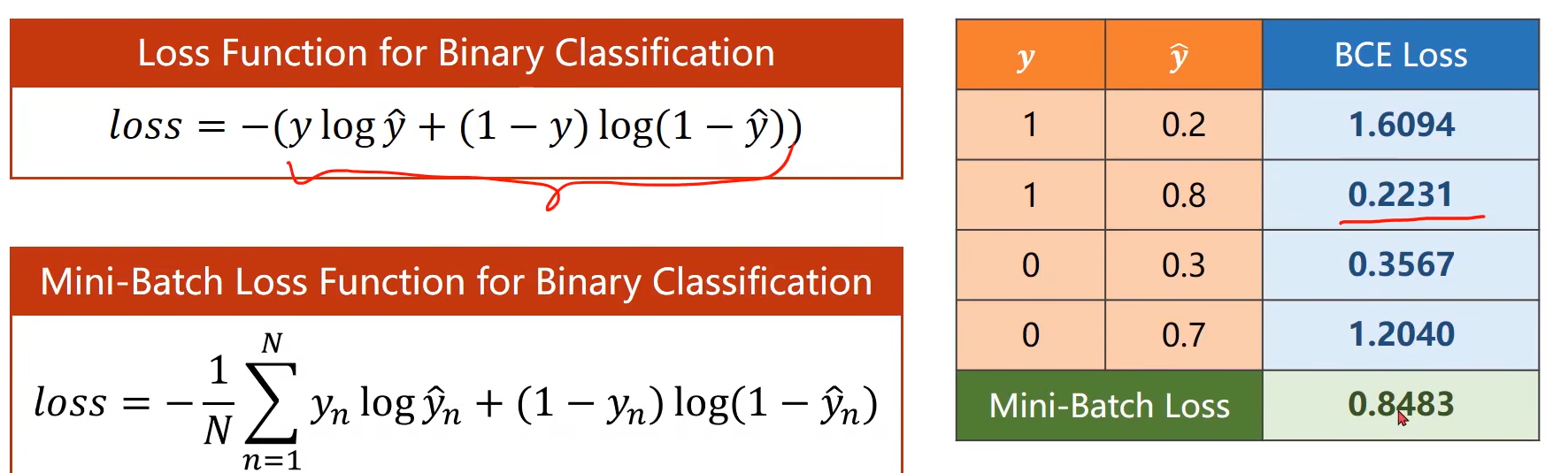
在代码上,只需要修改y_pred的结果 和 损失
这个求损失的方法,就是交叉熵
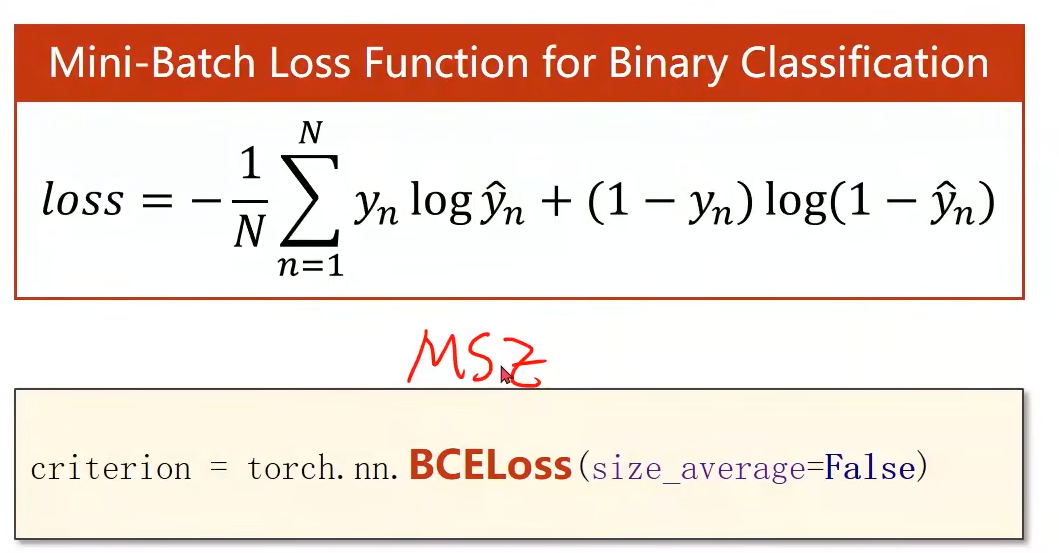
1 | import torch |
7. 多维数据处理
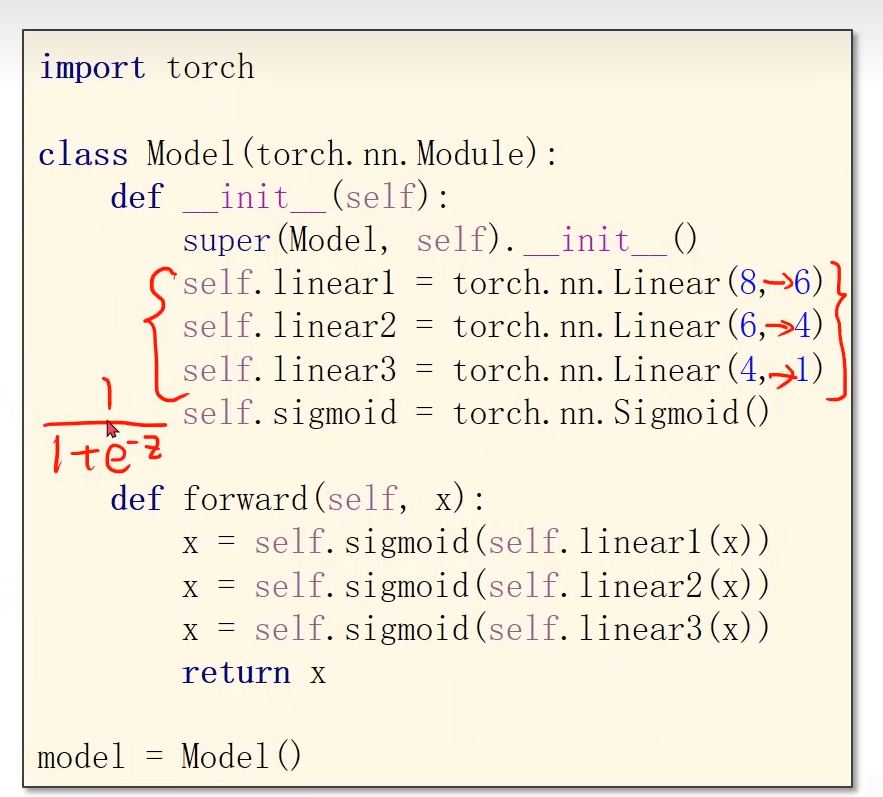
- 用多层神经网络,神经网络共3层;第一层是8维到6维的非线性空间变换,第二层是6维到4维的非线性空间变换,第三层是4维到1维的非线性空间变换。
- 本算法中
torch.nn.Sigmoid()将其看作是网络的一层,而不是简单的函数使用
博客:https://blog.csdn.net/bit452/article/details/109682078
1 | import numpy as np |
8. 加载数据集
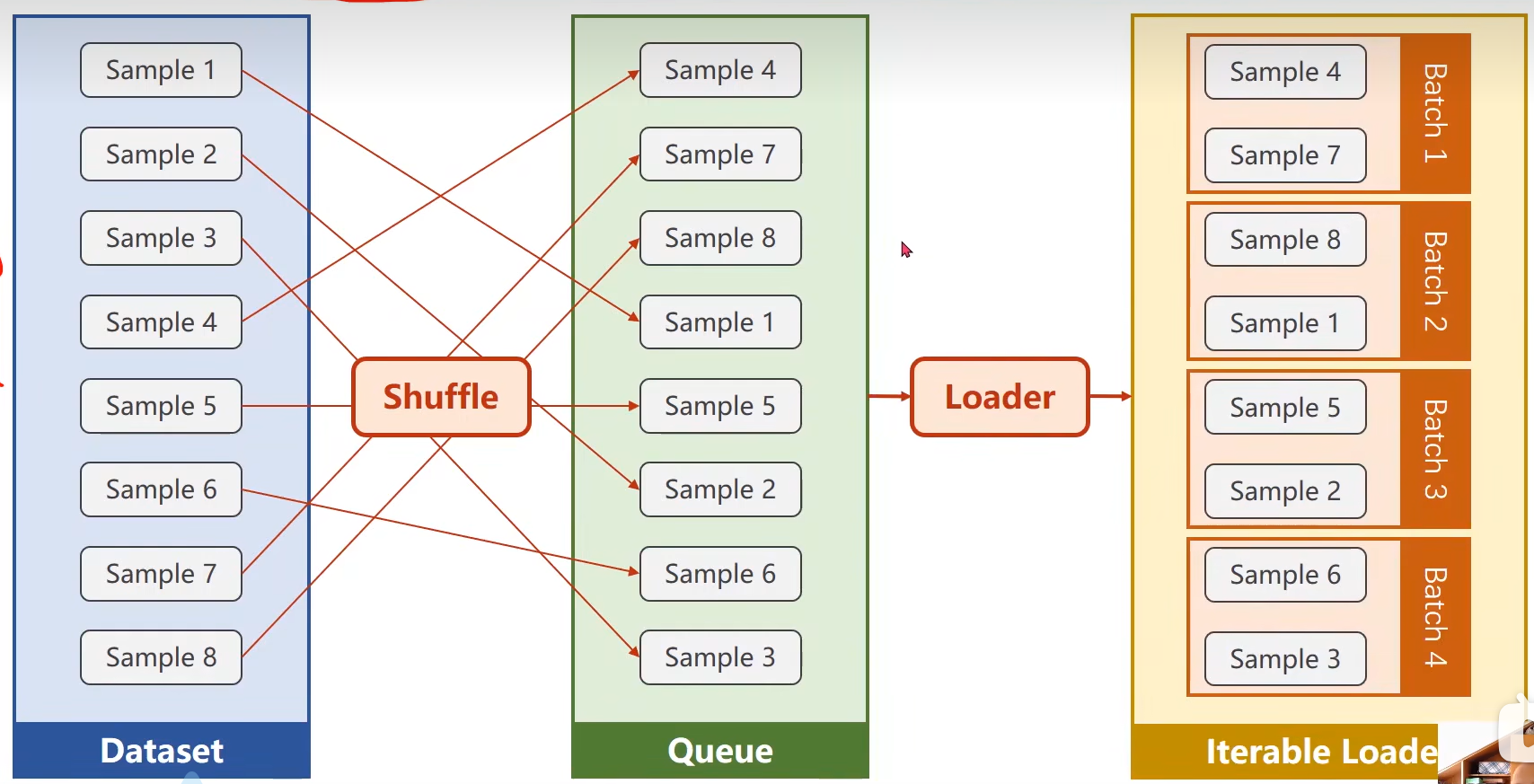
MiniBatch
对数据集打乱、分组
自己定义
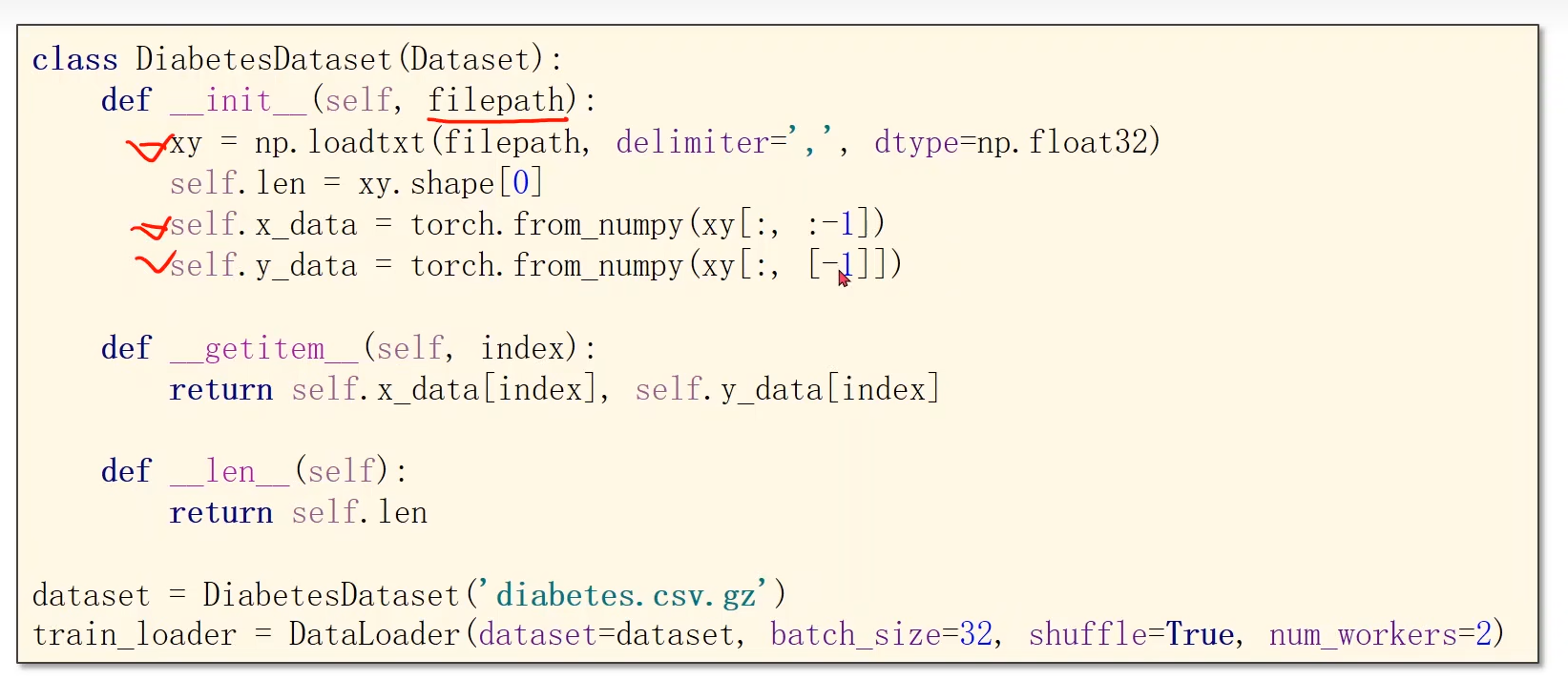
- DataSet 是抽象类,不能实例化对象,主要是用于构造我们的数据集
- DataLoader:数据加载器。能拿出Mini-Batch进行训练。它帮我们自动完成这些工作。DataLoader可实例化对象。
- batch_size:批处理大小
- shuffle:是否打乱,真正训练的时候都会打乱
- num_workers:并行处理的个数
- 继承DataSet的类需要重写init,getitem,len魔法函数。分别是为了加载数据集,获取数据索引,获取数据总量。

定义数据类
迭代数据对象。每次epoch用某一批的数据来训练。

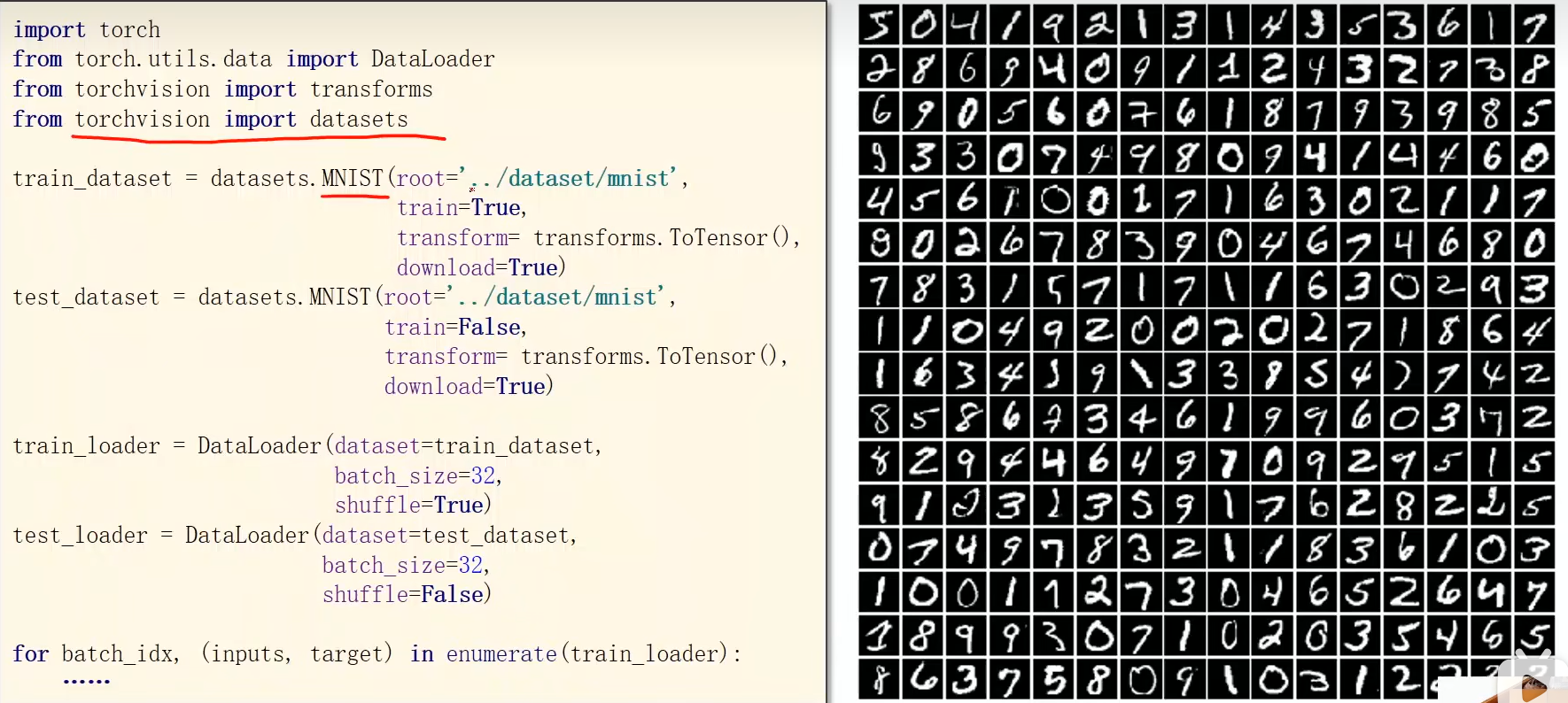
使用库中的数据集
内置了手写字体识别的数据集,datasets可以直接获取相关的数据对象
1 | import torch |
9. 多分类问题
9.1 Softmax
对每个分类求结果,如把看做求
y1,把其他的分类都看做P(y)=0.
那么求出结果,但是会造成,这些分类的结果相加不是1,比如P(y1) = 0.8,P(y2)=0.7
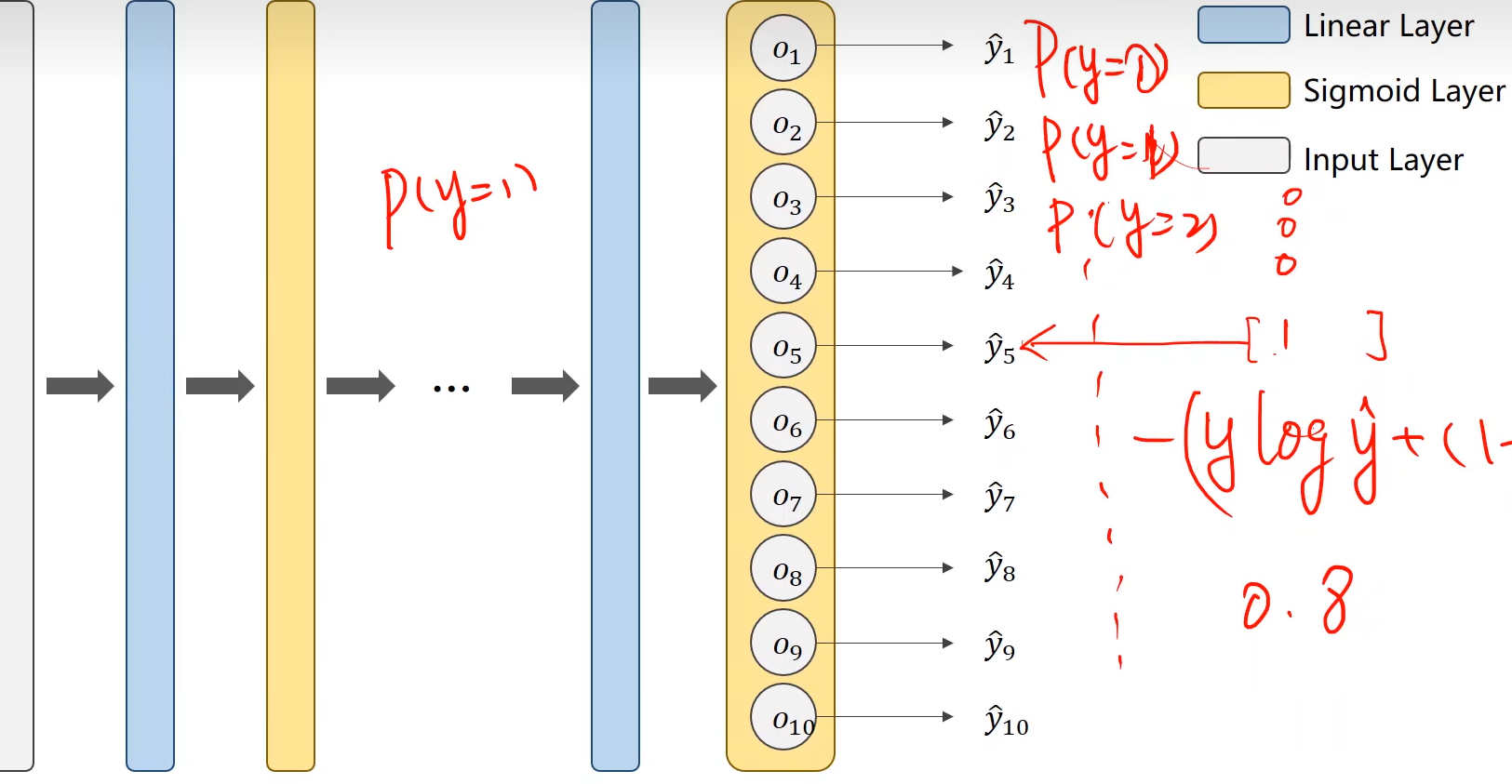
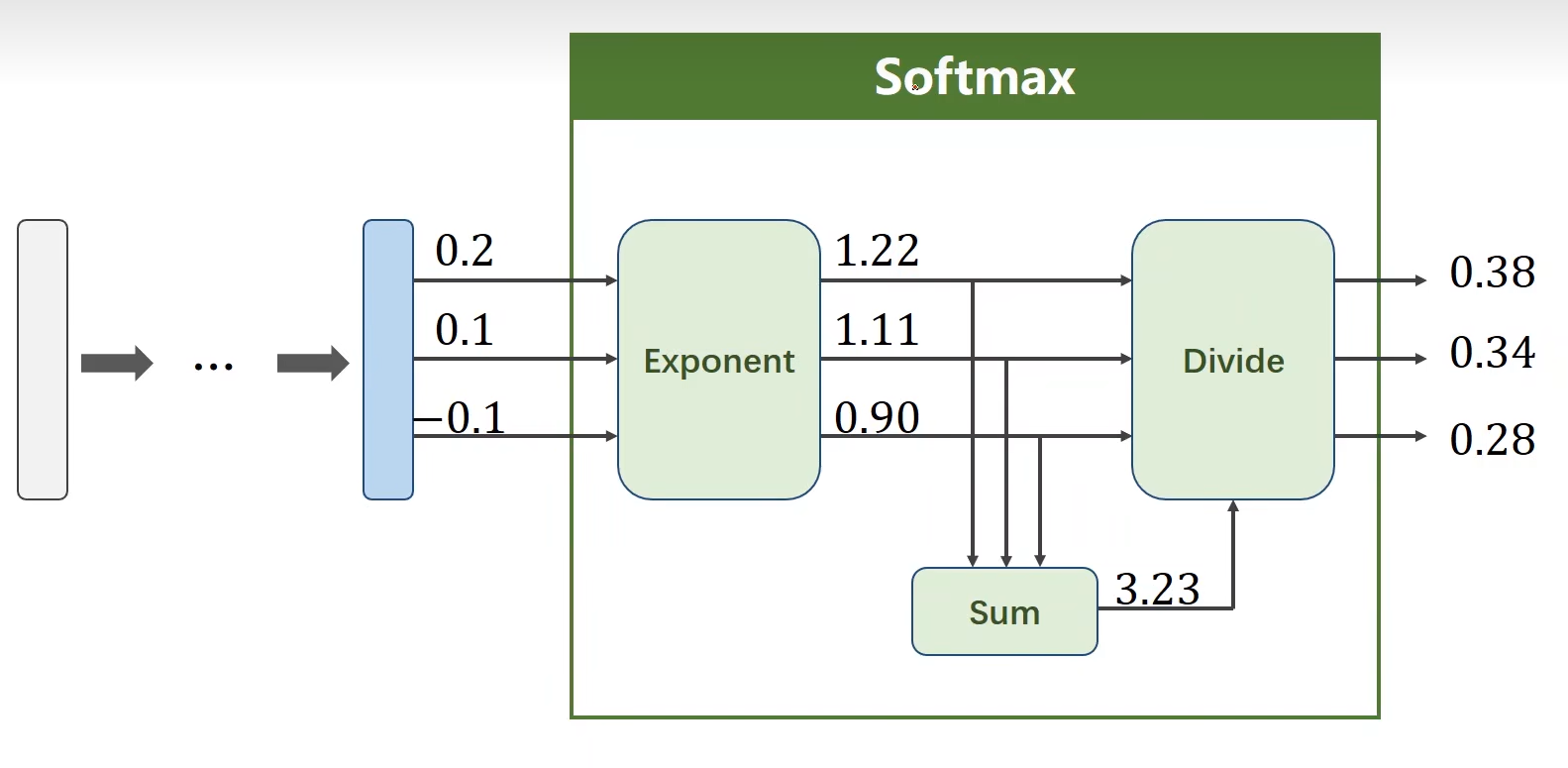
Softmax:重新得到一个值,然后求和,再求。即:a/a+b+c
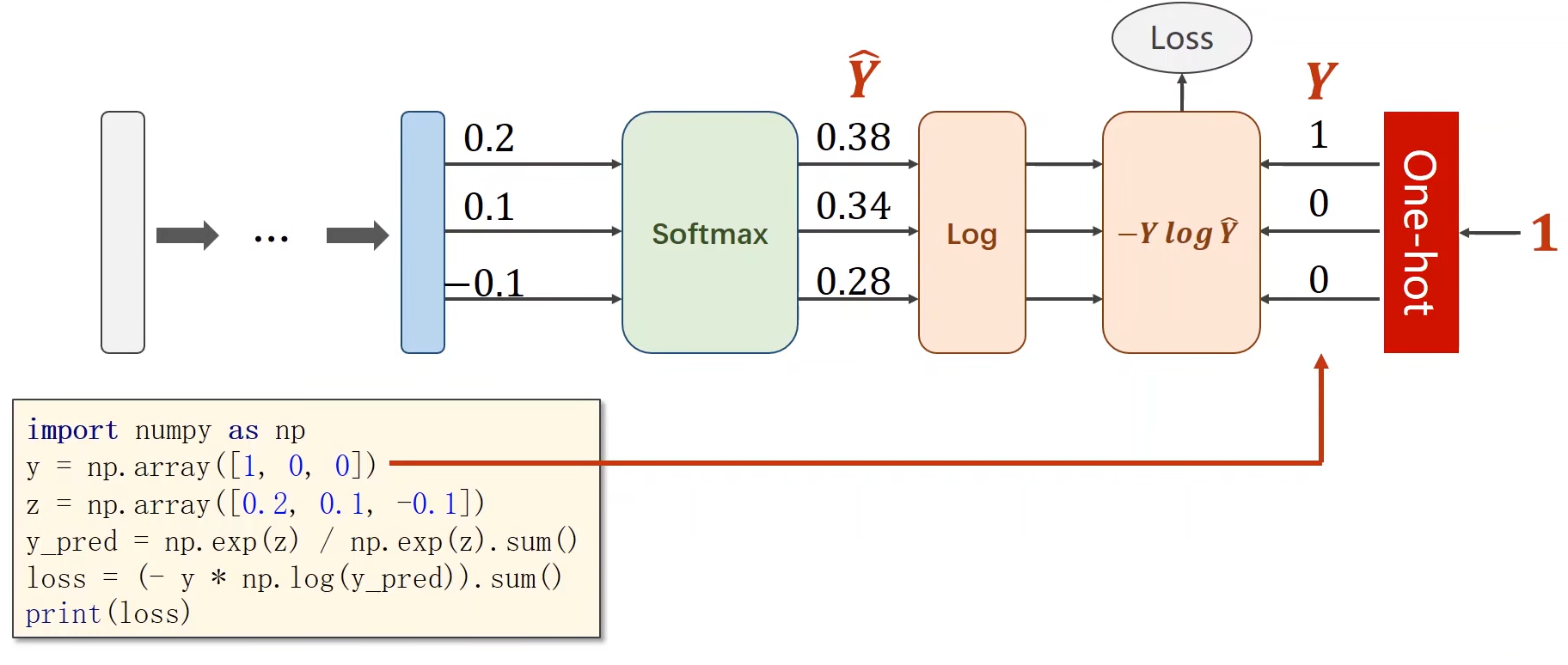
交叉熵求损失
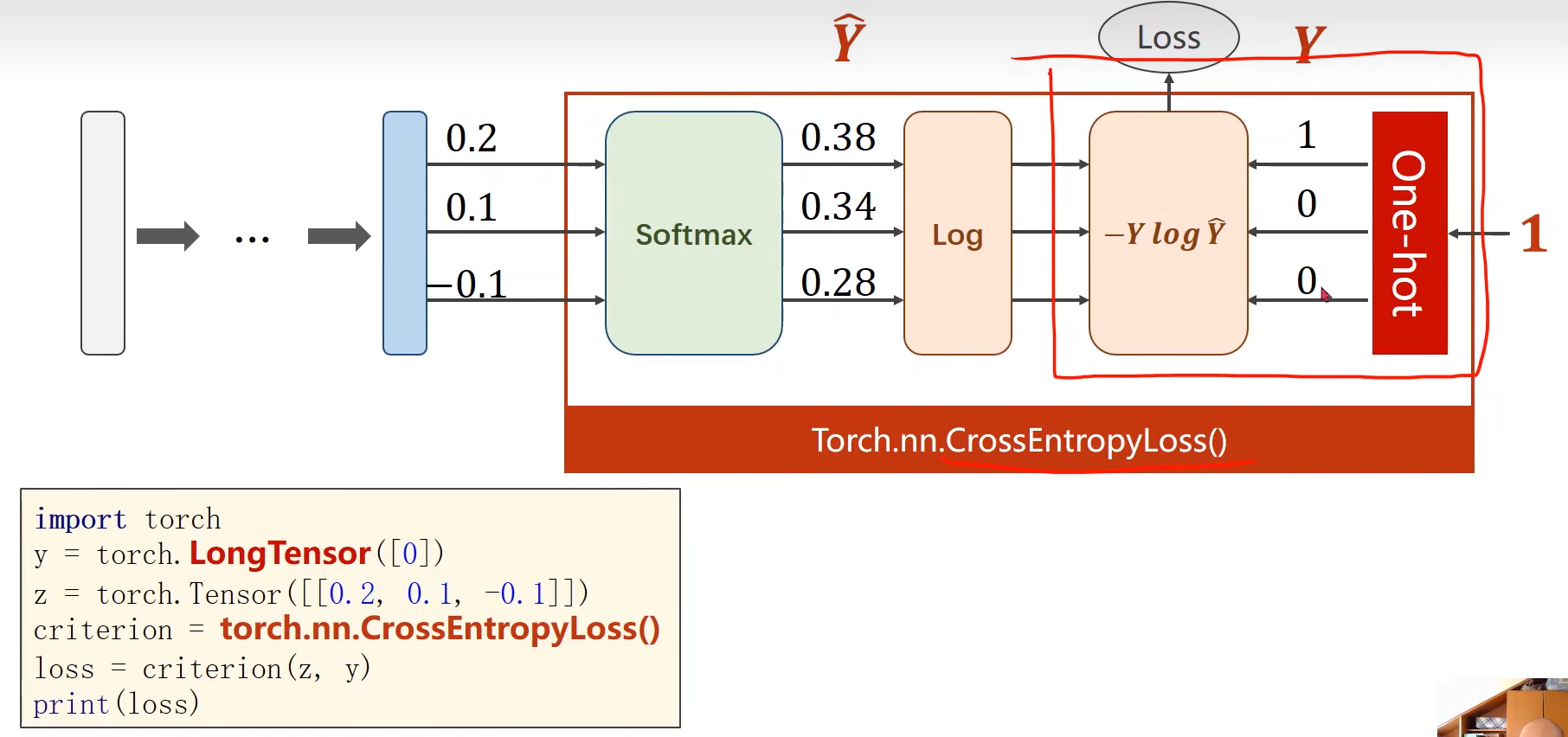
用CrossEntropyLoss,神经网络的最后一层不需要做激活
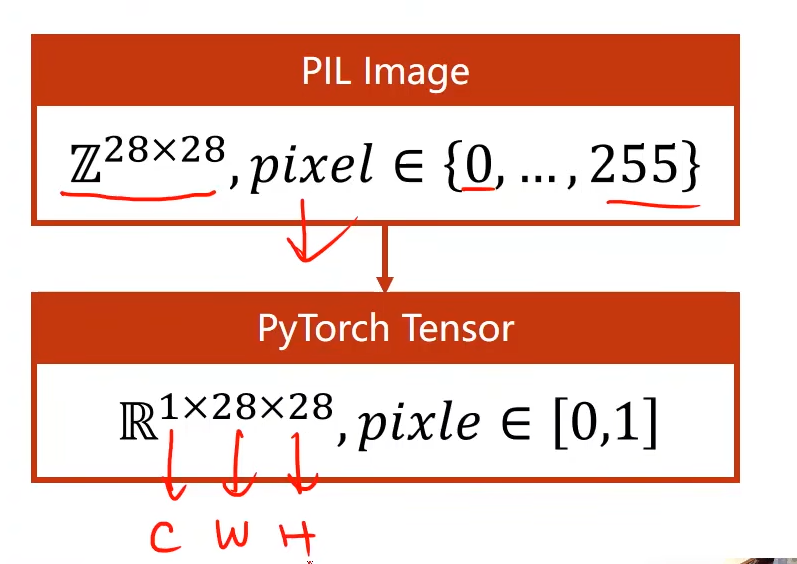
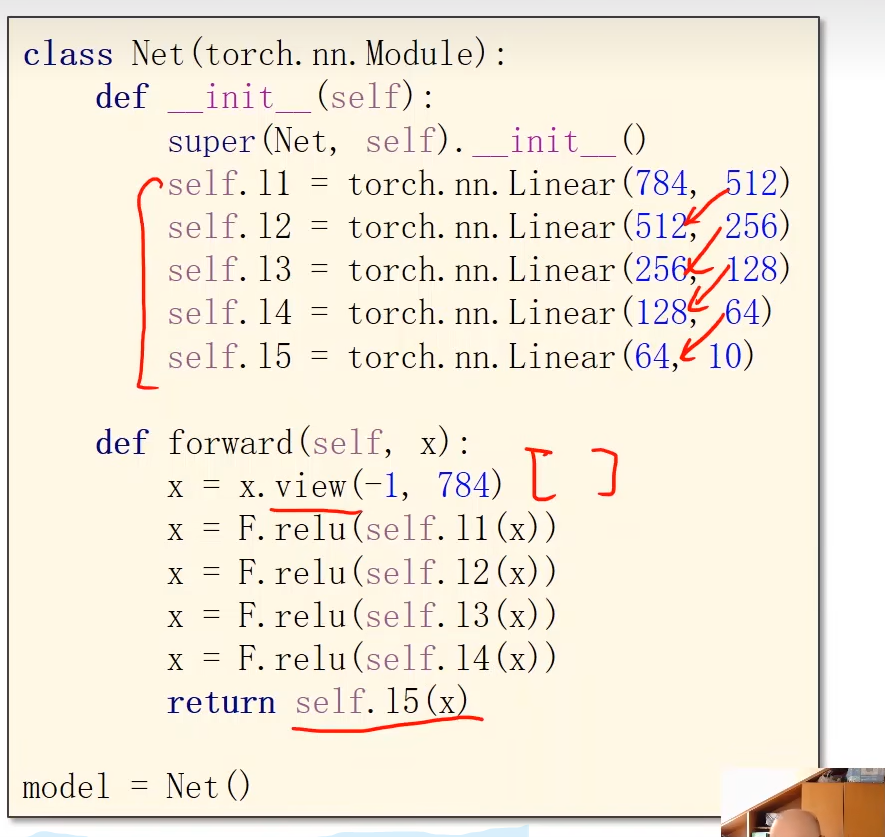
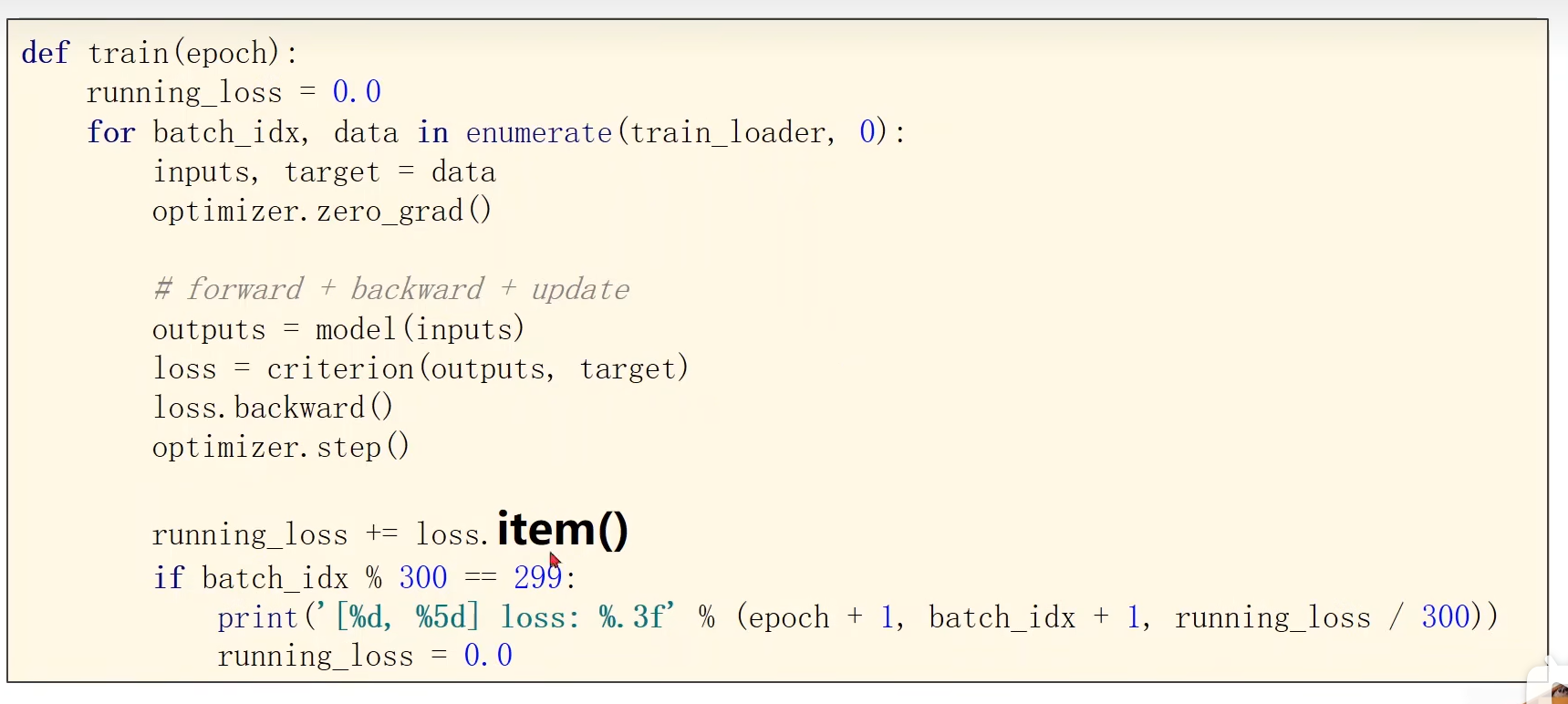
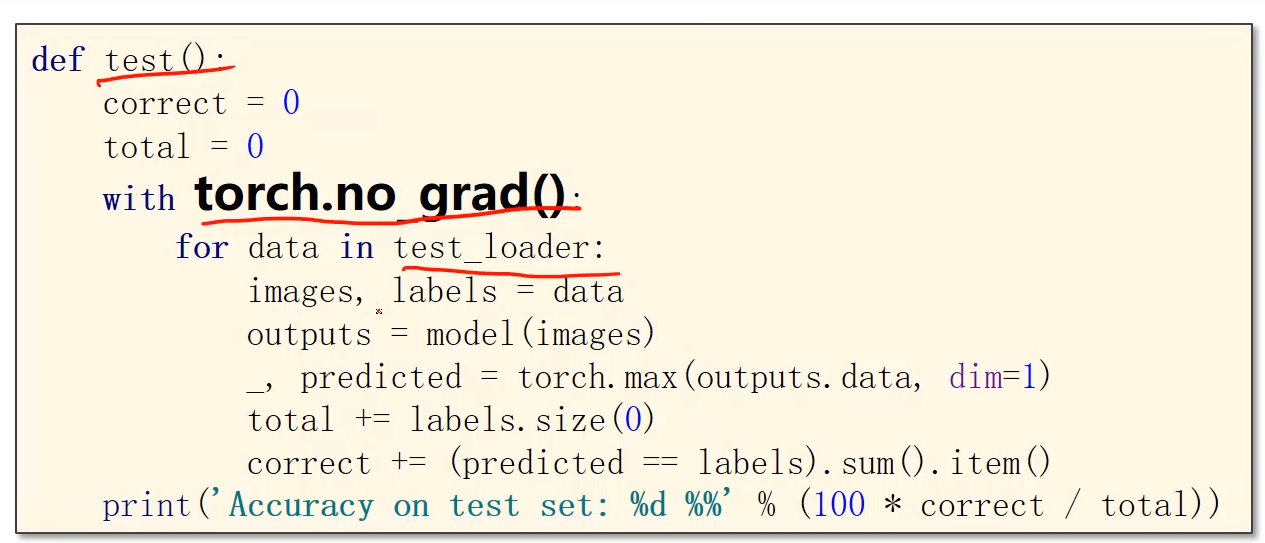
9.2 图像输入表示
一张黑白图的像素,可以用0-255的数值表示

图像的表示
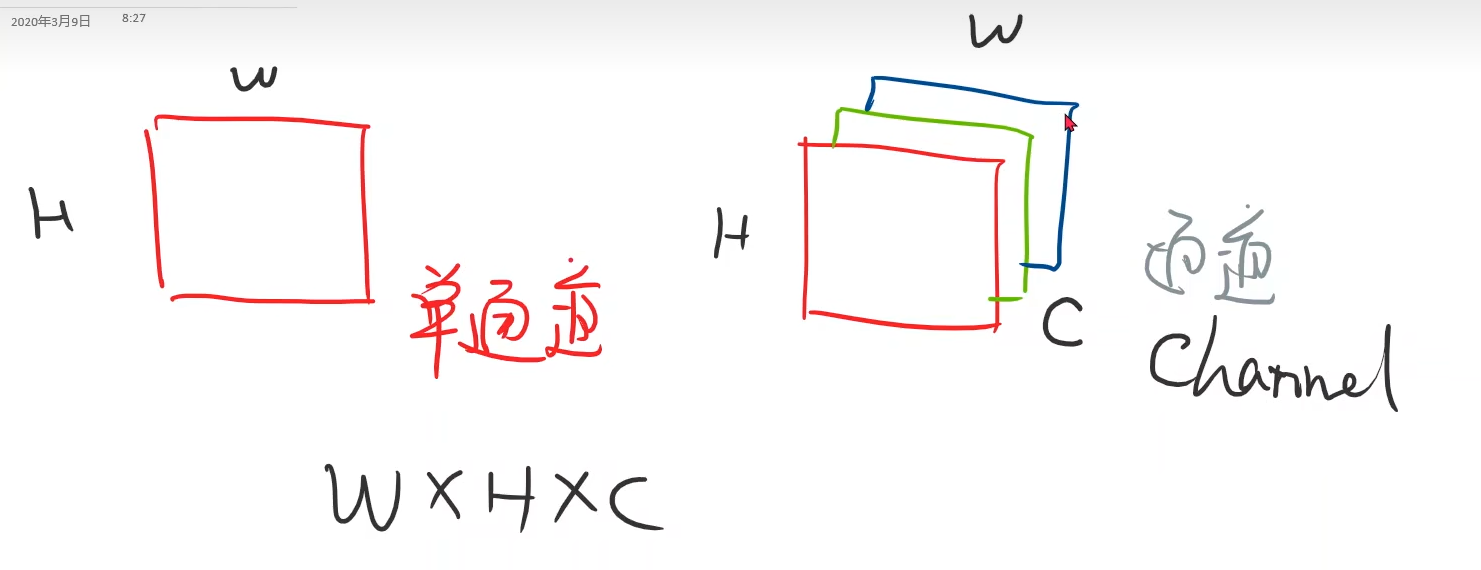
将图像转为Tensor,分别是:通道、宽、高
全连接网络
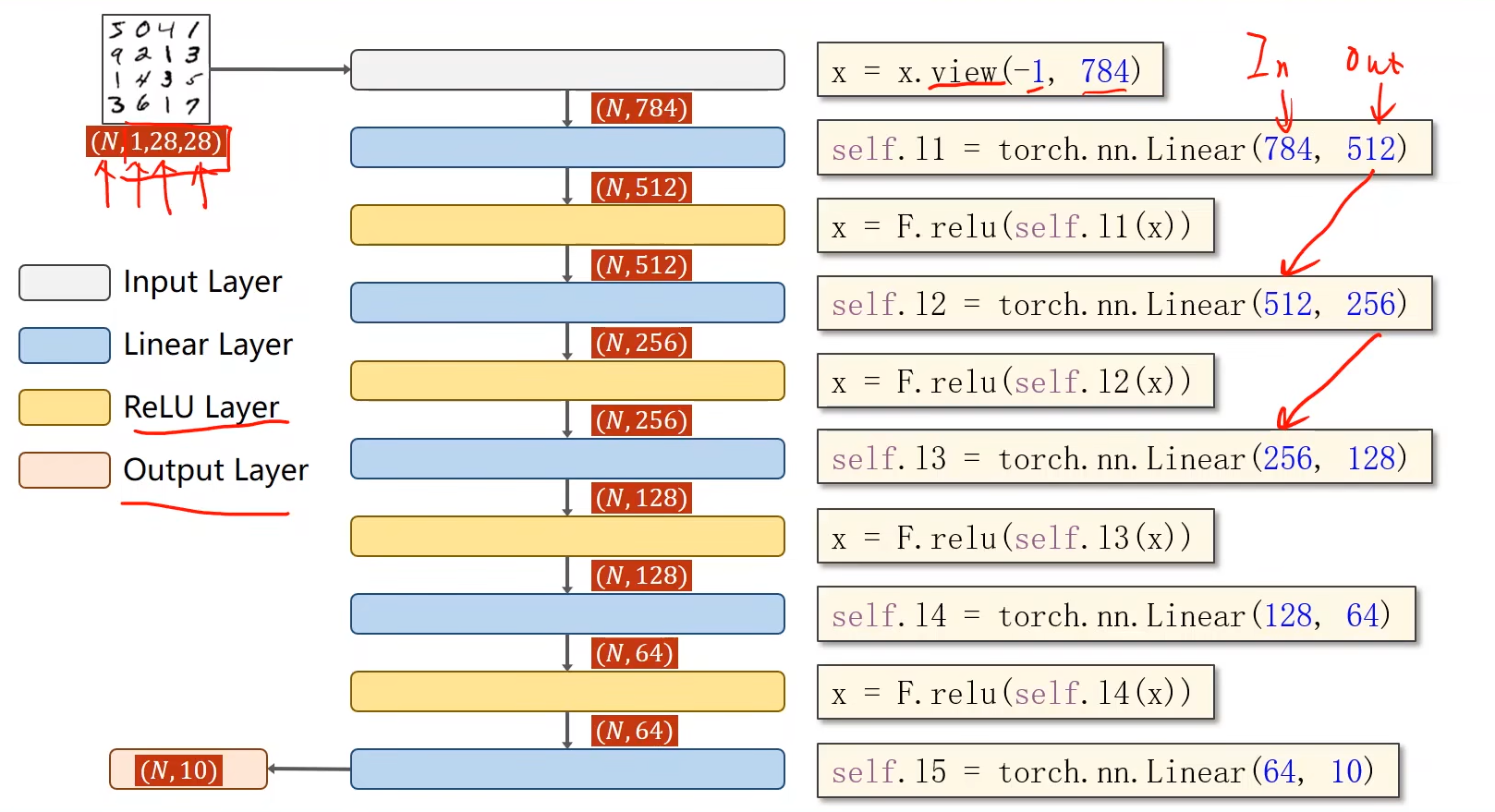
最后一层不做激活
9.3 总结
来自:https://blog.csdn.net/bit452/article/details/109686936
- softmax的输入不需要再做非线性变换,也就是说softmax之前不再需要激活函数(relu)。softmax两个作用,如果在进行softmax前的input有负数,通过指数变换,得到正数。所有类的概率求和为1。
- 多分类问题,标签y的类型是LongTensor。比如说0-9分类问题,如果y = torch.LongTensor([3]),对应的one-hot是[0,0,0,1,0,0,0,0,0,0].(这里要注意,如果使用了one-hot,标签y的类型是LongTensor,糖尿病数据集中的target的类型是FloatTensor)
- CrossEntropyLoss <==> LogSoftmax + NLLLoss。也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log操作。
1 | import torch |
10. 卷积神经网络
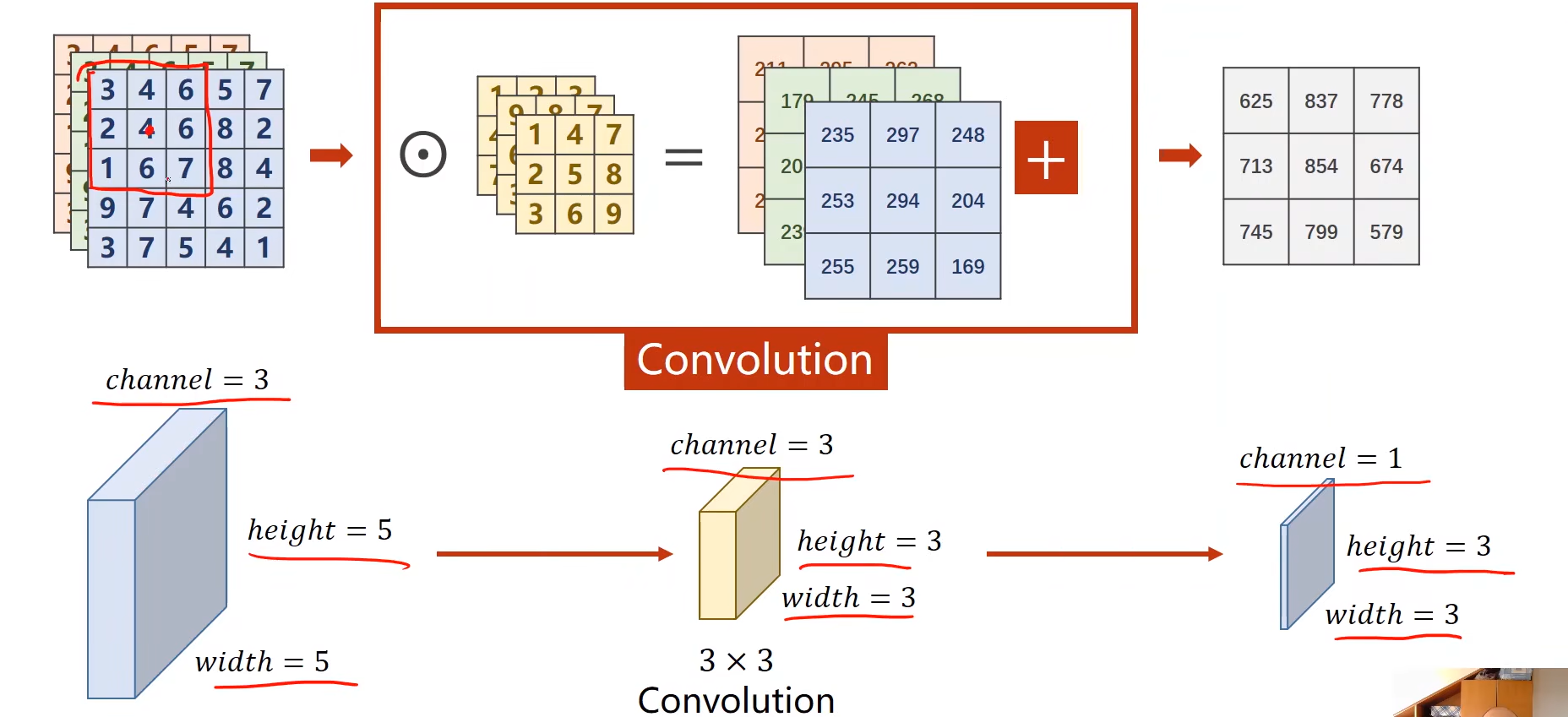
假如一个RGB的图片,有三个通道,即
C * W *H的张量。
卷积的过程:用卷积核转为一个通道(提取特征),生成新的C'*W'*H'的张量,最大池化层进一步减小,最后转为一个向量。
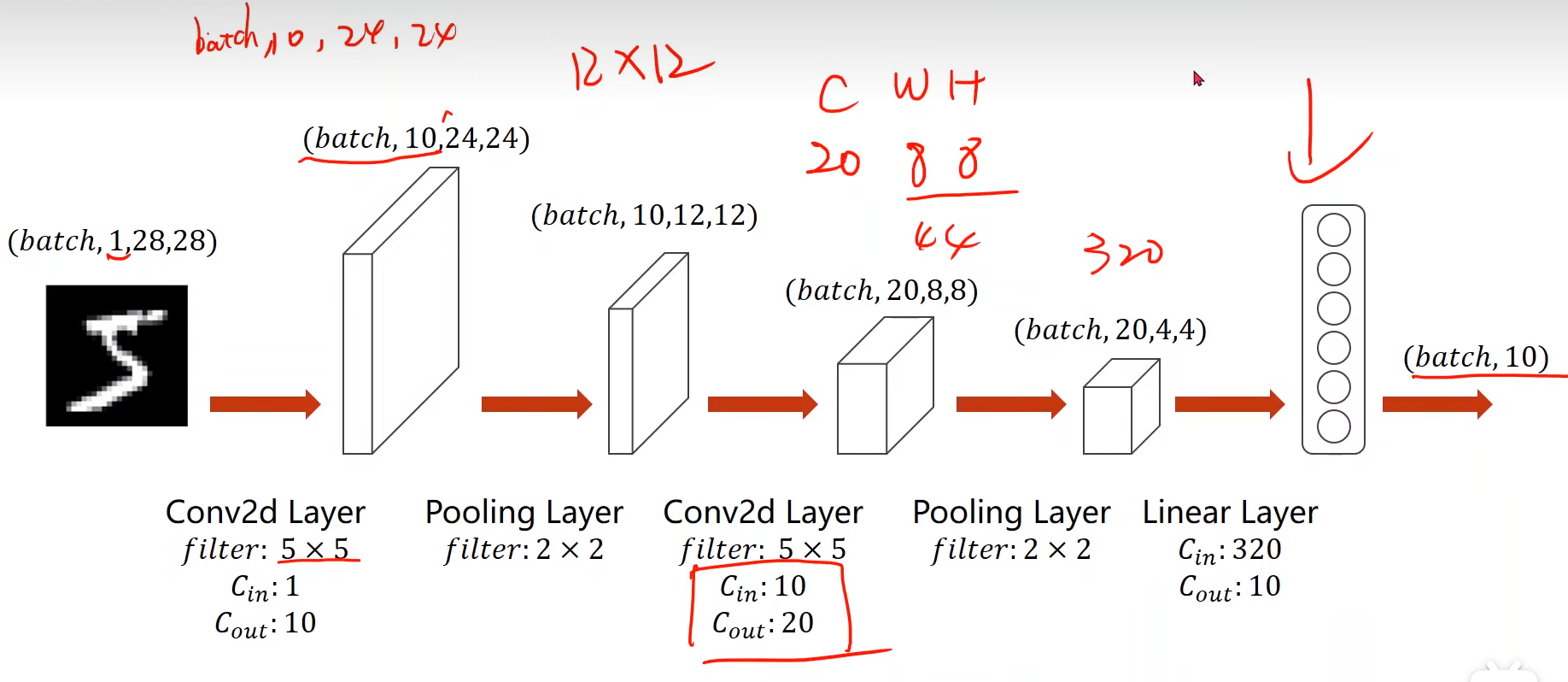
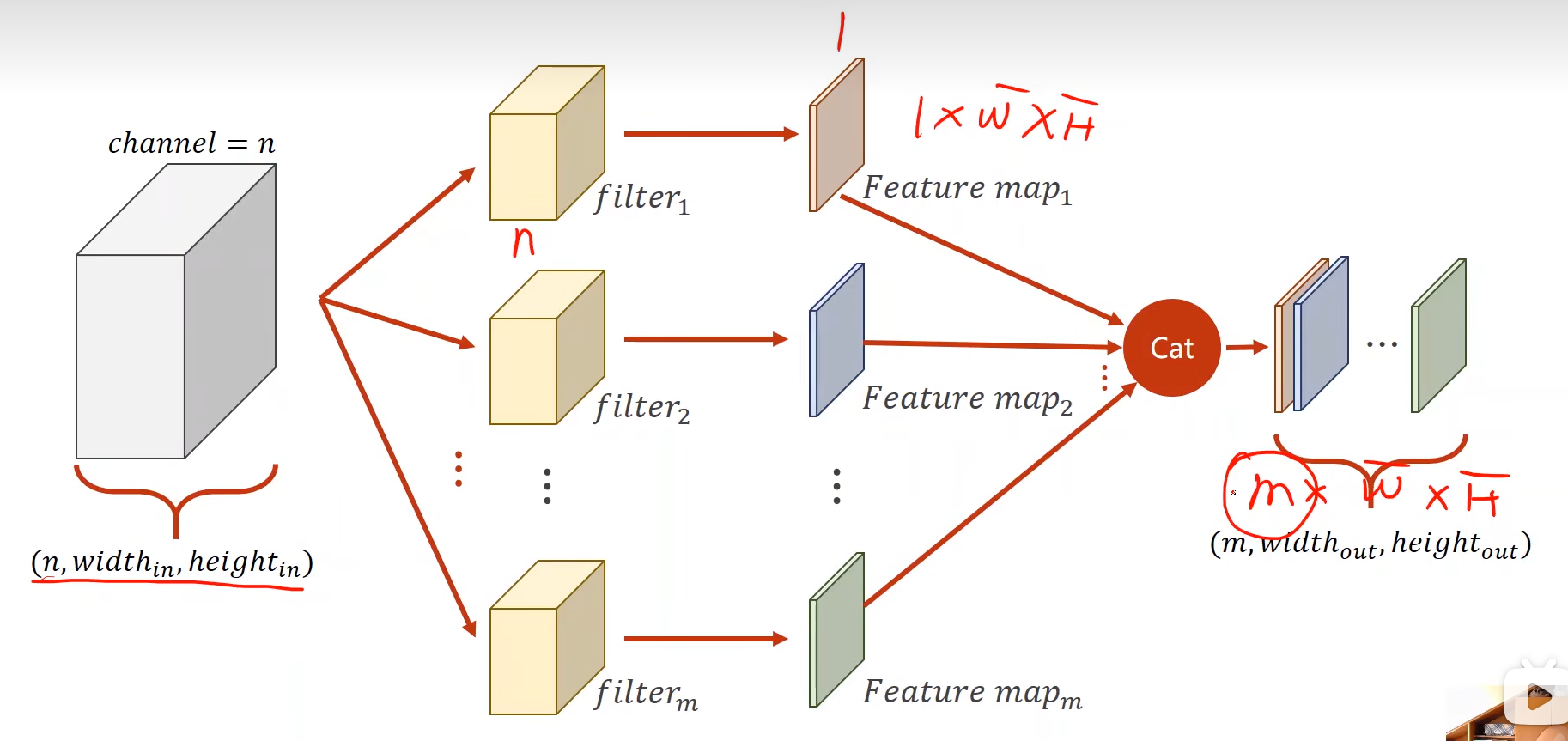
另一种情况,想要多个输出通道

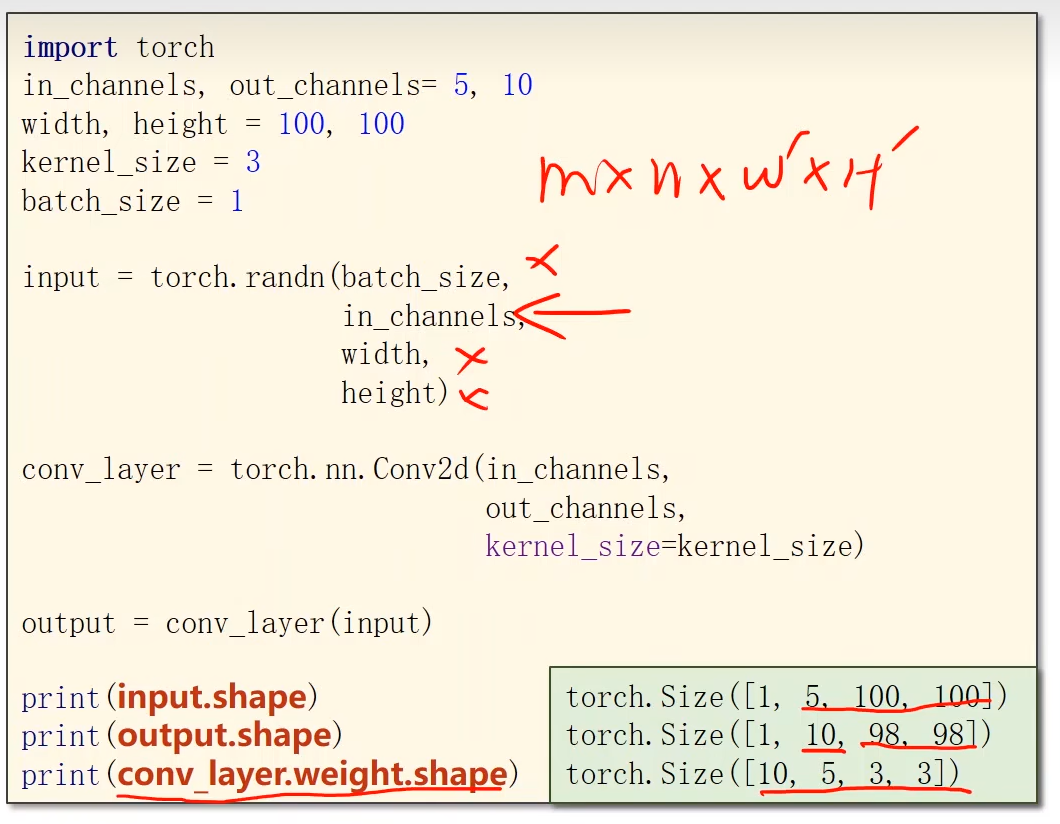
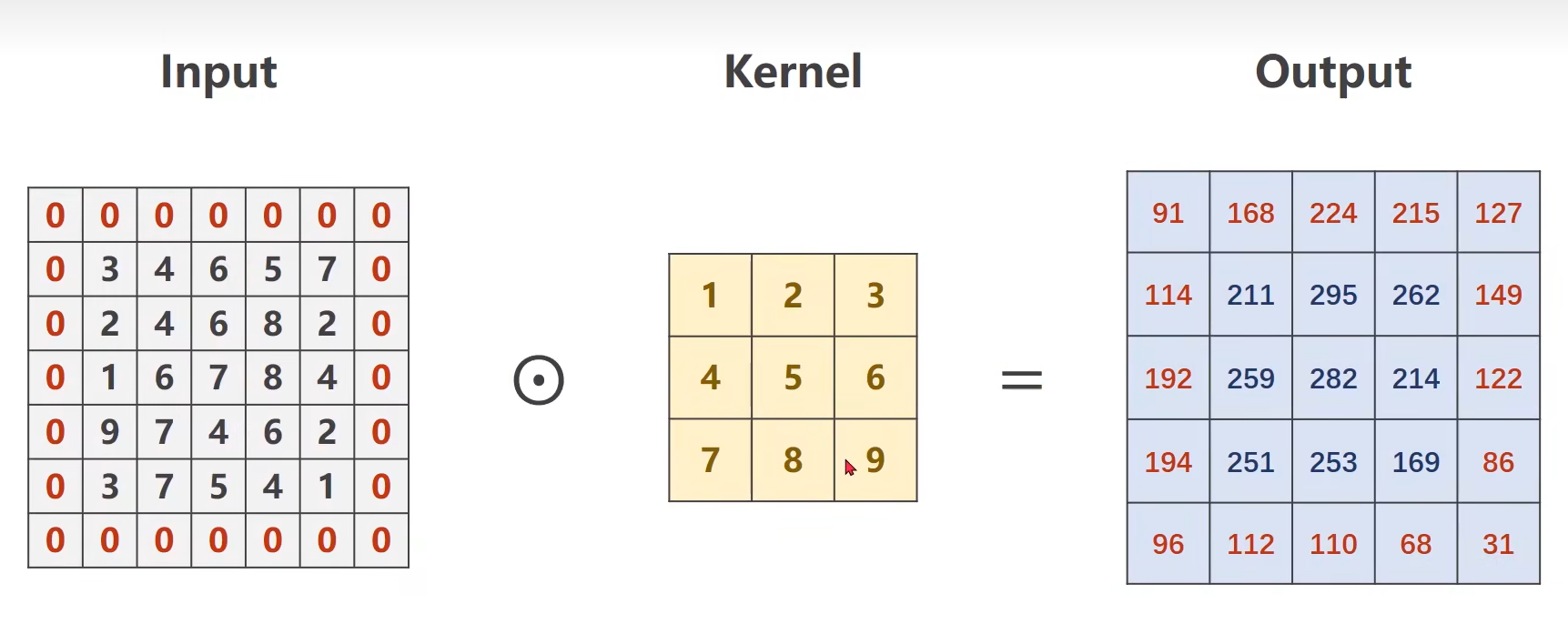
10.1 padding
weight.data,自己定义卷积核权重

10.2 stride 步长
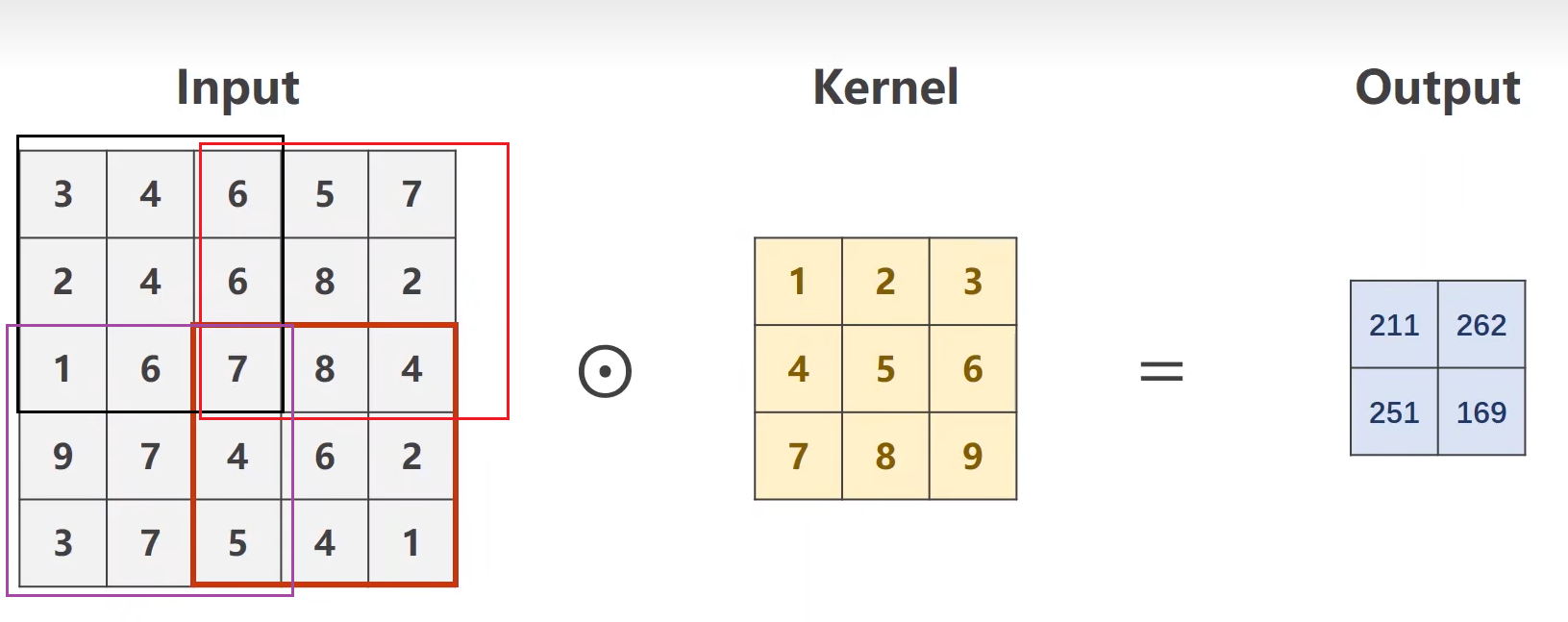

10.3 下采样
MaxPooling
分成四块,选最大的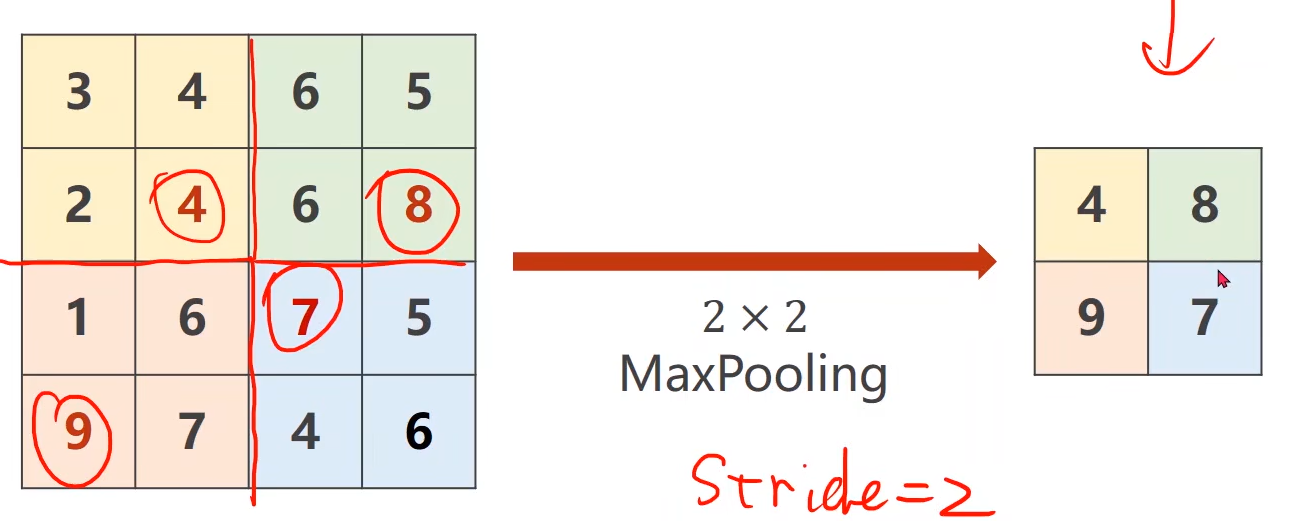
设置kernel_size=2,默认步长也是2
10.4 卷积神经网络过程

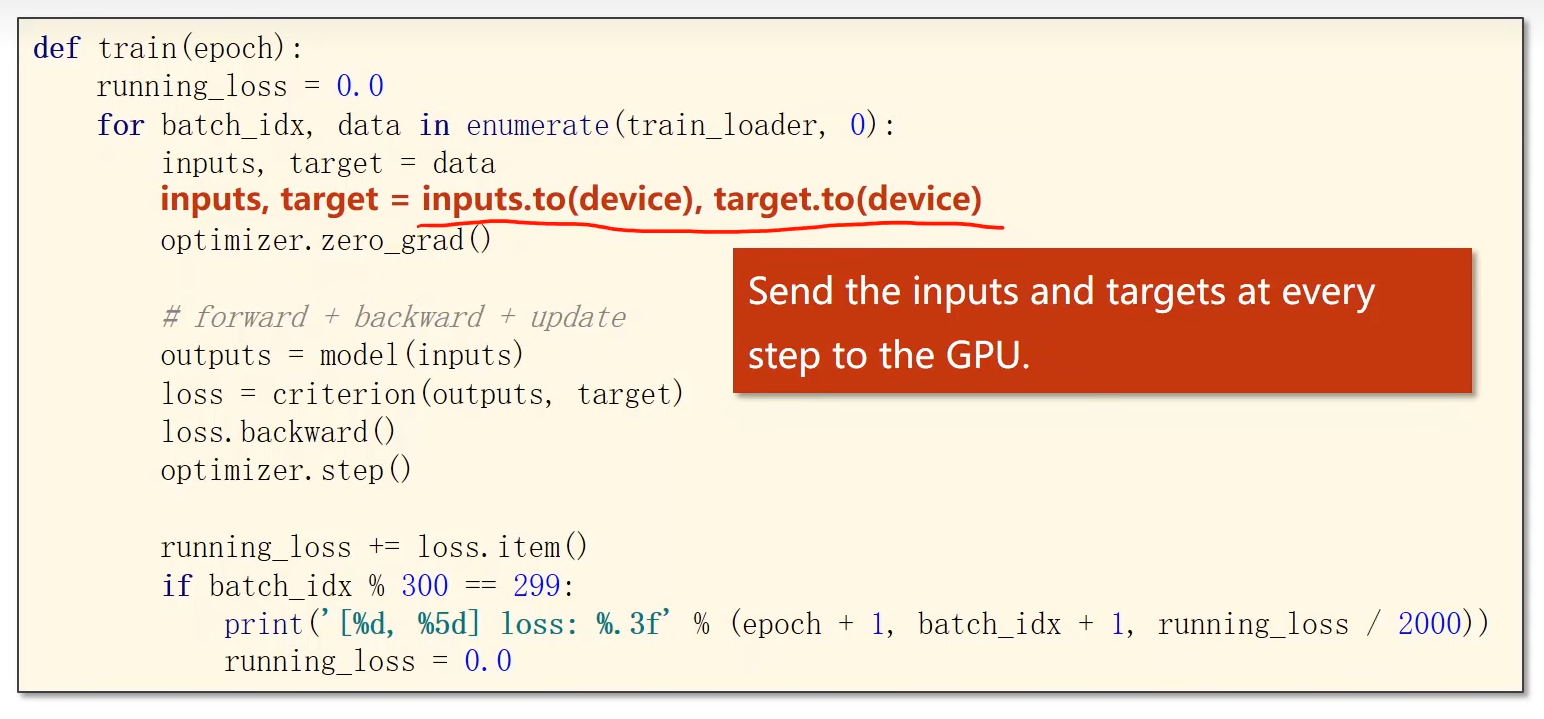
10.5 GPU运行
用GPU

1 | # This is a sample Python script. |
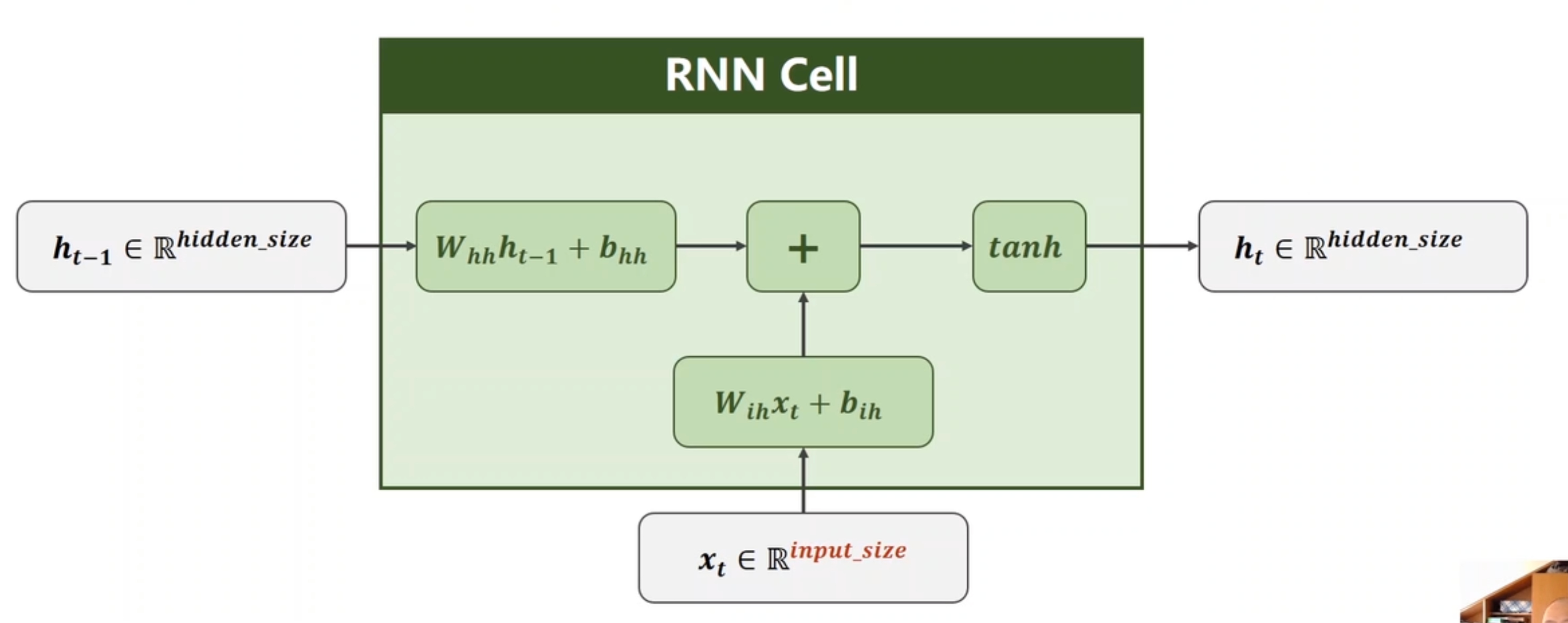
11. RNN 循环神经网络
是一种用于处理序列数据的神经网络架构。它特别适合于处理时间序列、自然语言处理和其他顺序数据,因为它能够捕获数据的时间依赖性和动态信息。
内部实际上是线性层
每次都有前一个输出也同时作为输入进入cell计算。注意,第一个cell的h,可以自定义成全0;也可以接入其他,比如卷积的数据,作为卷积神经网络和循环神经网络的一个链接作用。
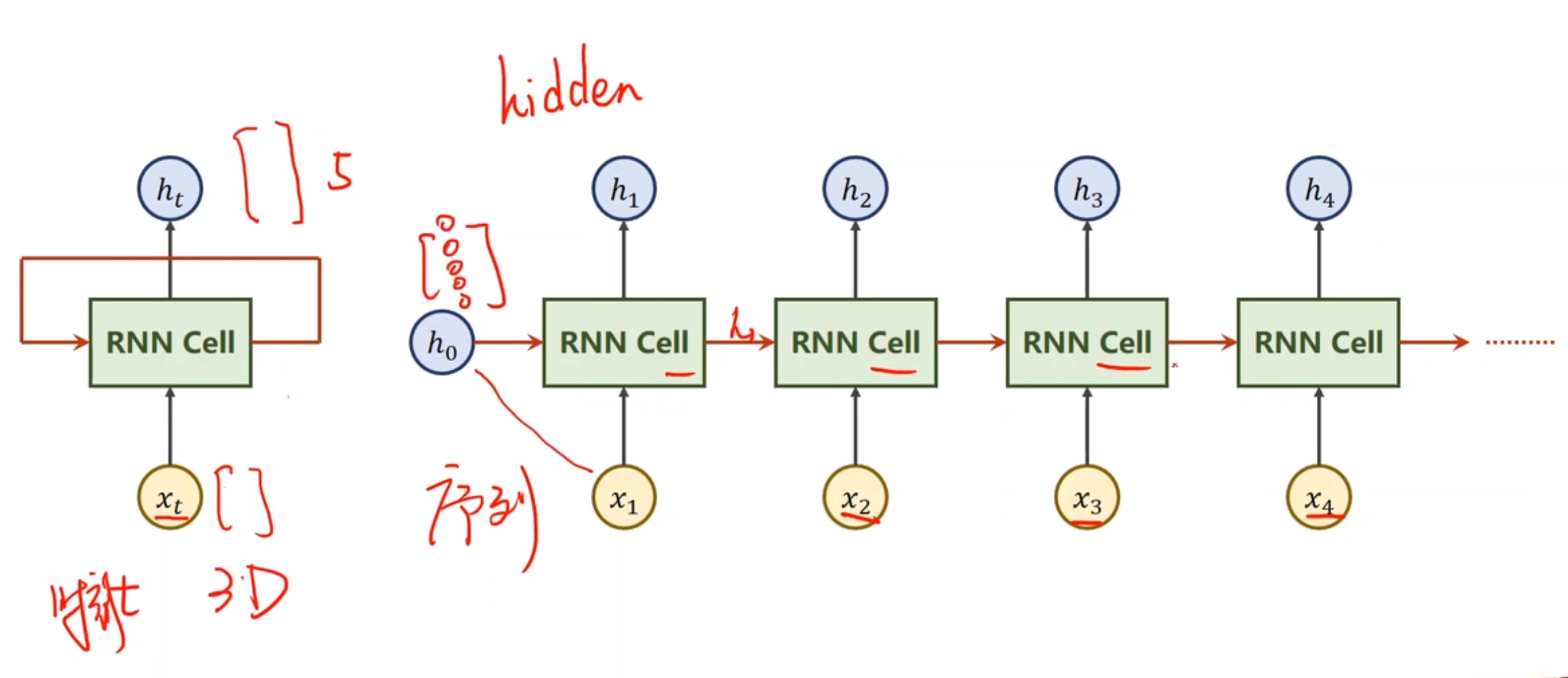

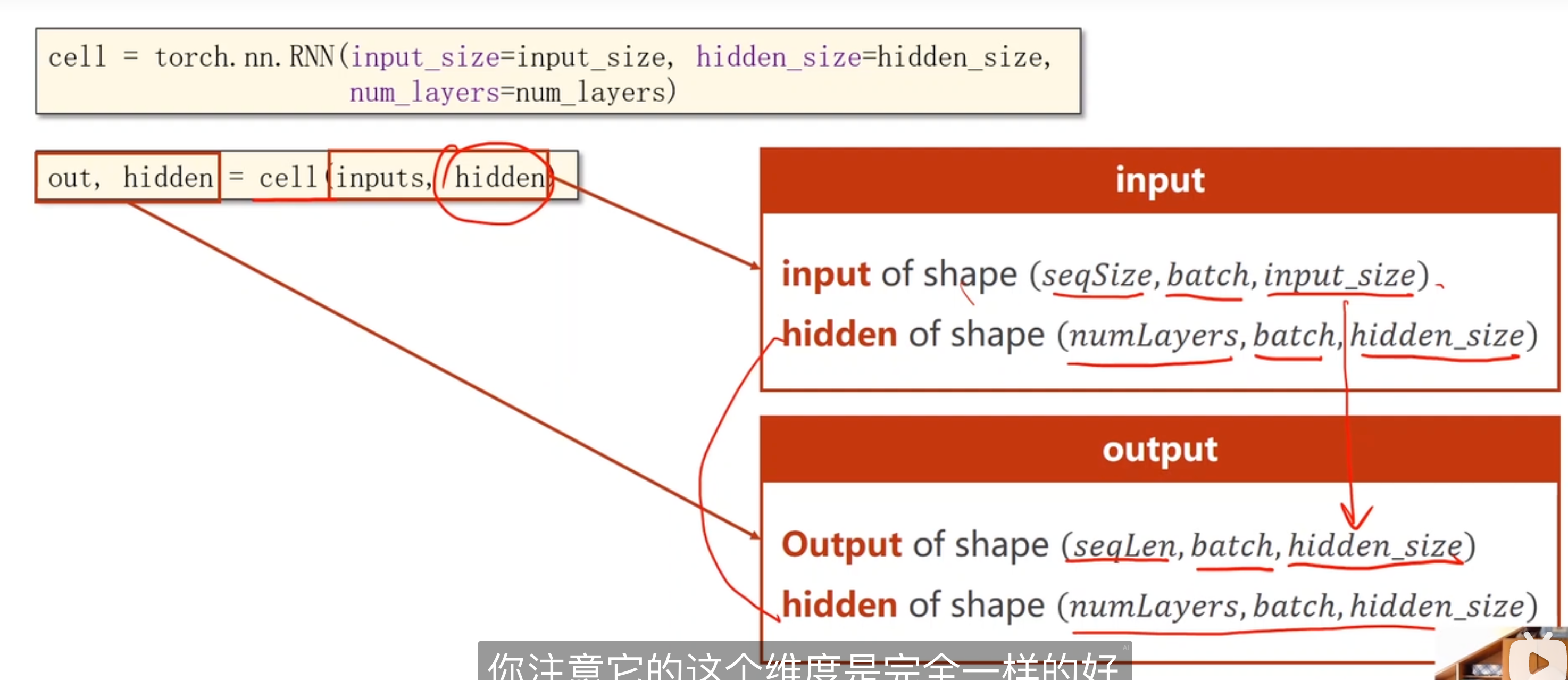
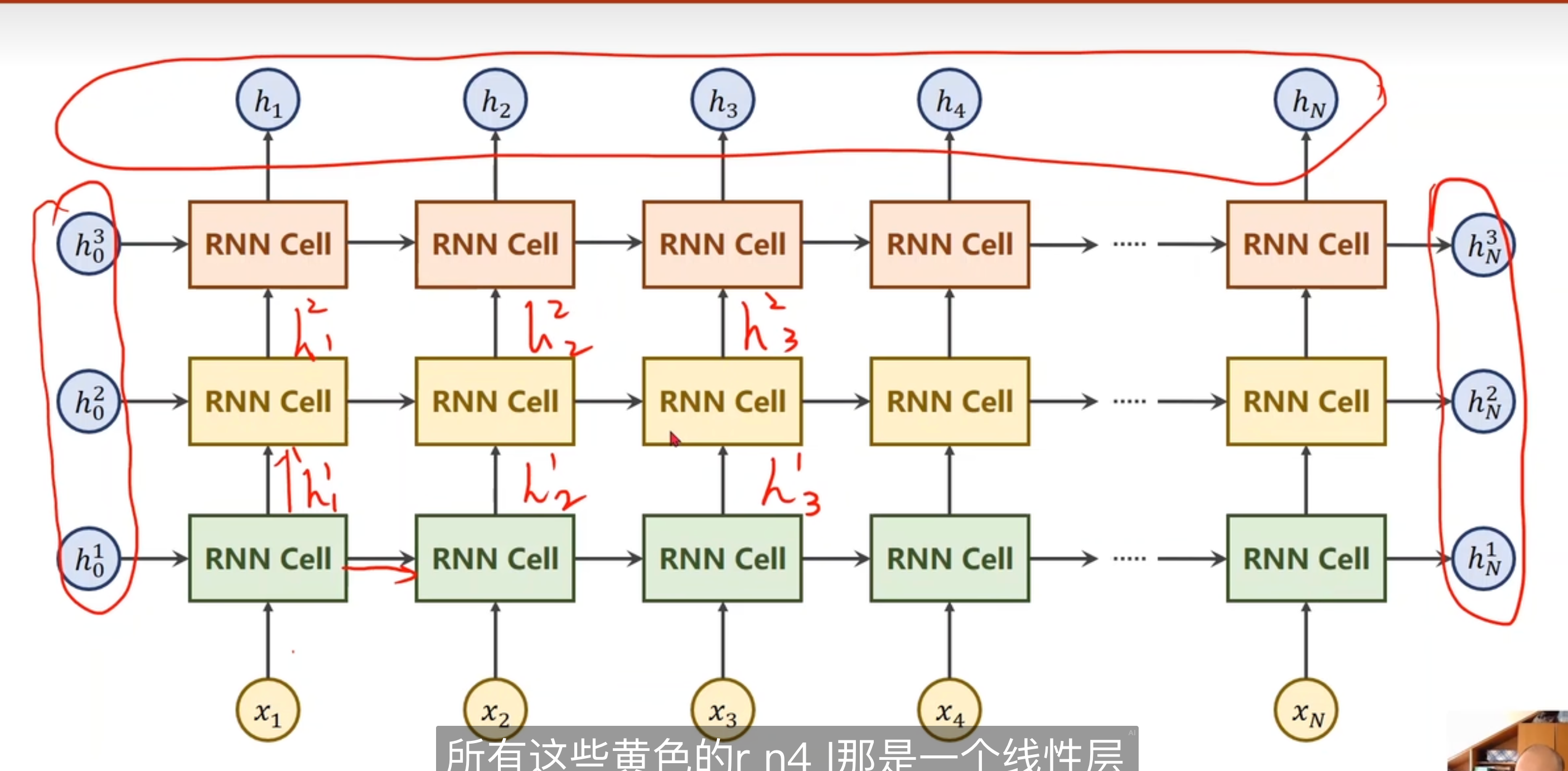
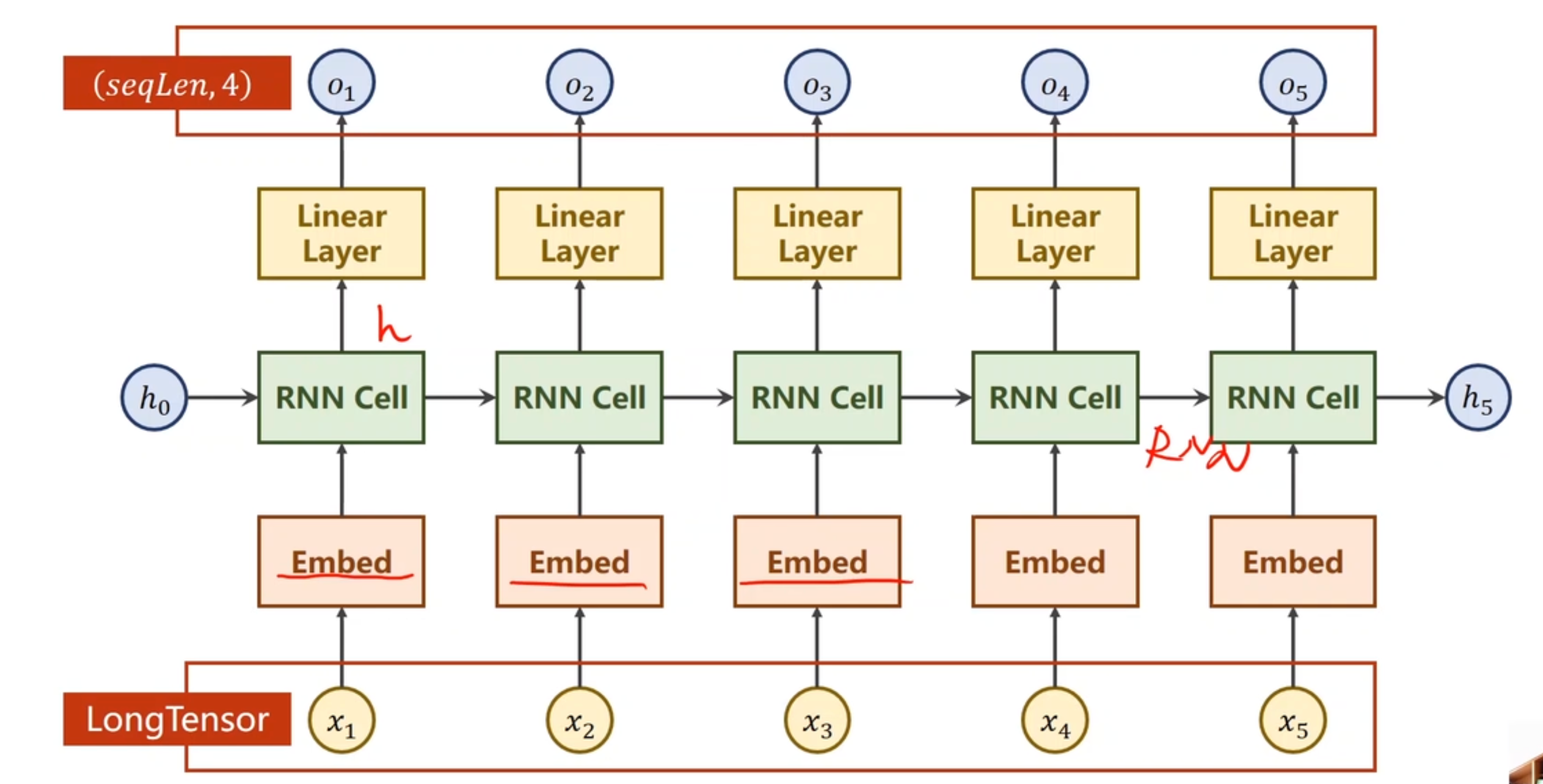
多层RNN
训练代码,RNN内部已经实现了循环
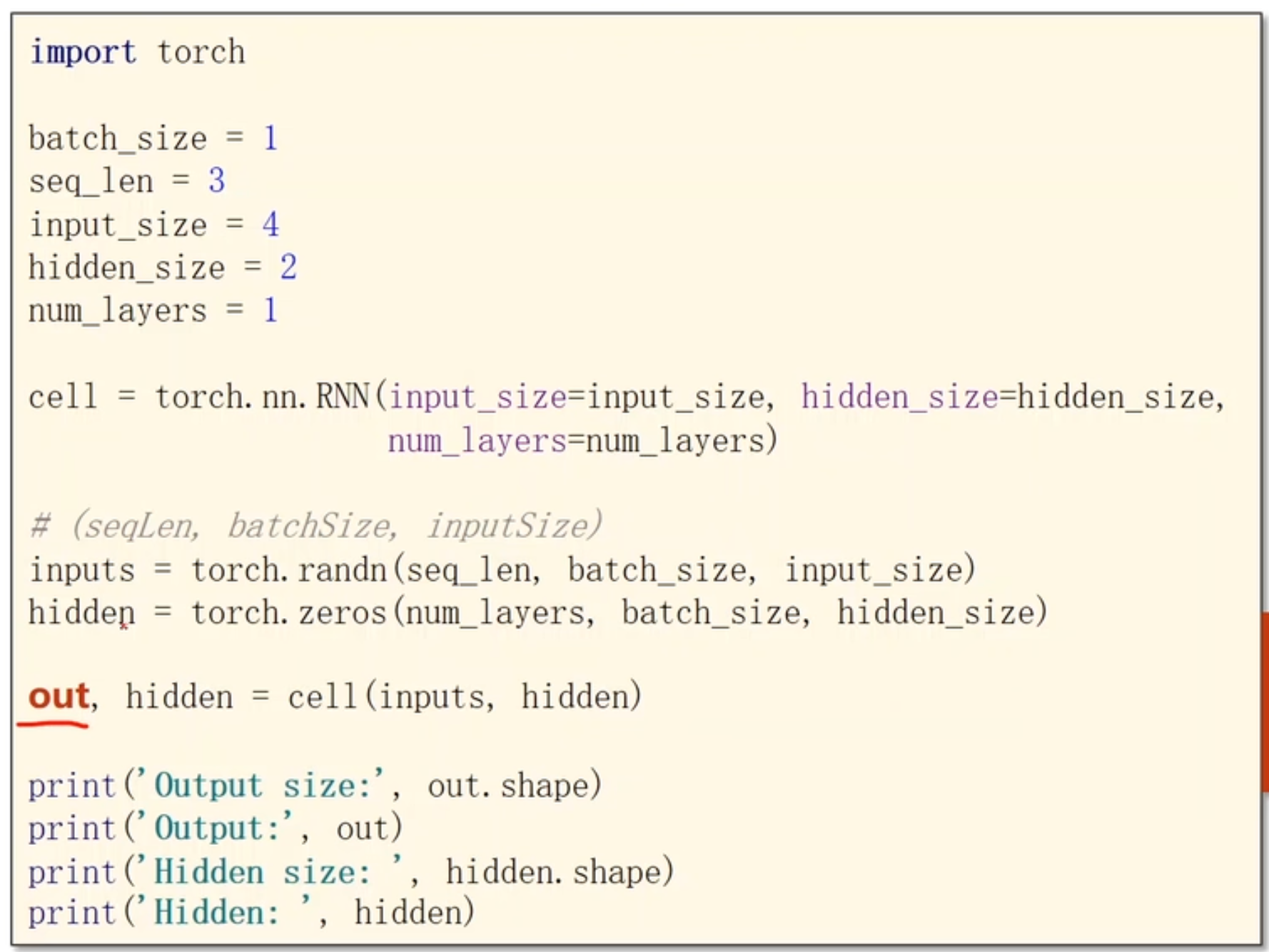
交换batch_size和seq_len的位置,有时将batch_size放到第一个纬度可能在其他用处上更方便

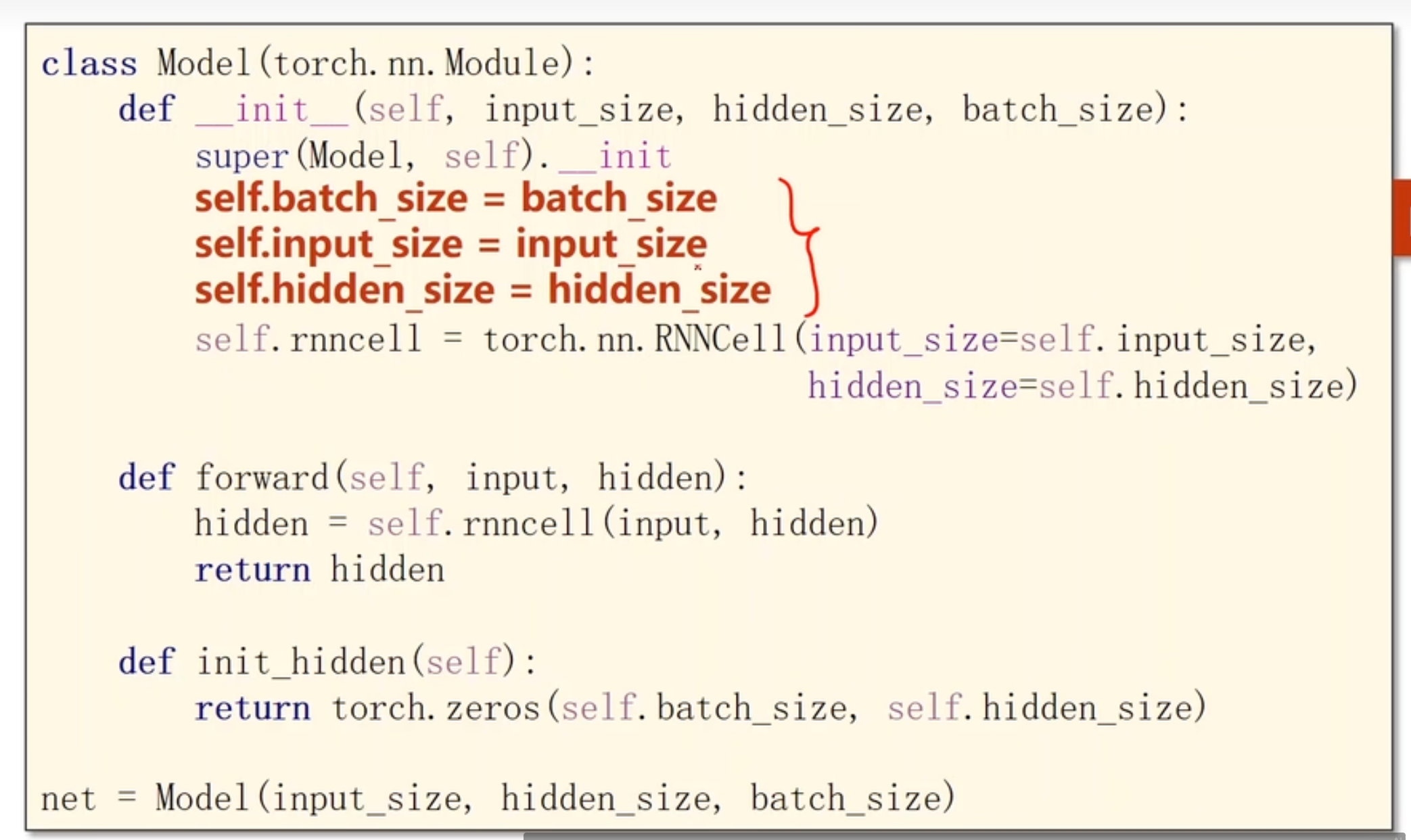
11.1 RNN Cell代码
假设是训练 hello –> e hlol
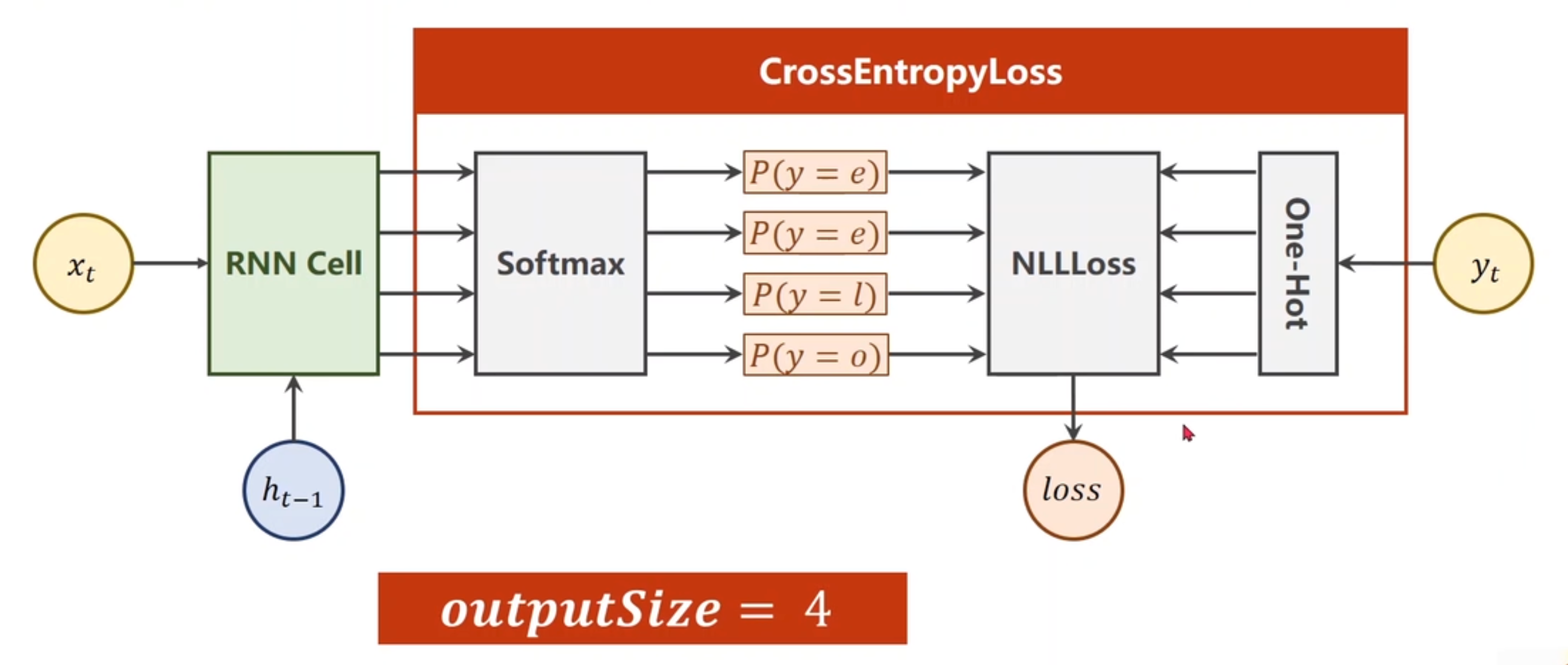
用独热向量来表示seq


定义模型
这里用的是RNNCell,而不是整个RNN


11.2 RNN


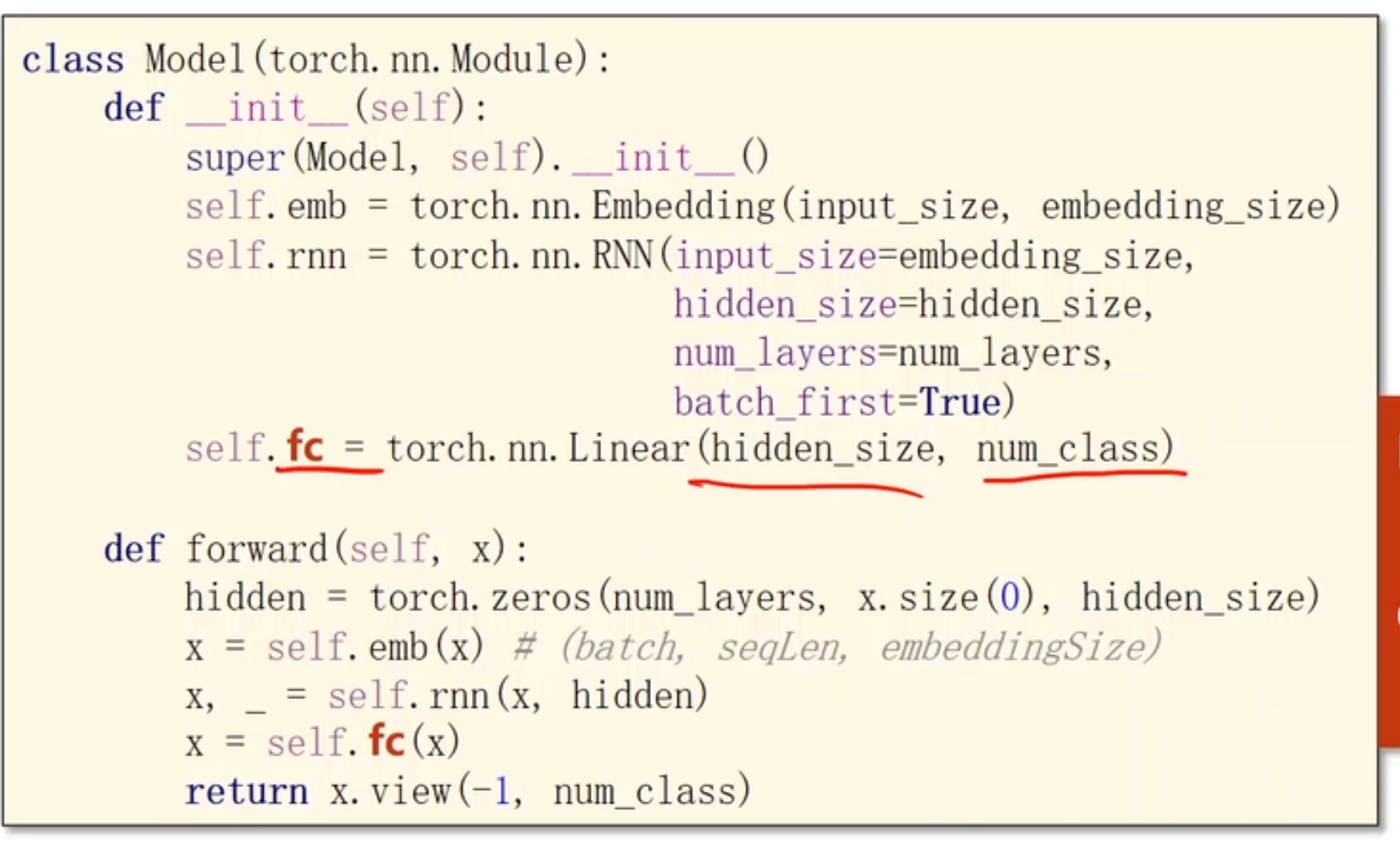
11.3 使用embedding
seq编码使用embedding


1 | PYTHONUNBUFFERED=1;LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/lib64:/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/opskernel:/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/nnengine:$LD_LIBRARY_PATH;ASCEND_TOOLKIT_HOME=/usr/local/Ascend/ascend-toolkit/latest;PYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages:/usr/local/Ascend/ascend-toolkit/latest/opp/built-in/op_impl/ai_core/tbe:$PYTHONPATH;PATH=/usr/local/Ascend/ascend-toolkit/latest/bin:/usr/local/Ascend/ascend-toolkit/latest/compiler/ccec_compiler/bin:$PATH;ASCEND_AICPU_PATH=/usr/local/Ascend/ascend-toolkit/latest;ASCEND_OPP_PATH=/usr/local/Ascend/ascend-toolkit/latest/opp;TOOLCHAIN_HOME=/usr/local/Ascend/ascend-toolkit/latest/toolkit;ASCEND_HOME_PATH=/usr/local/Ascend/ascend-toolkit/latest |
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



