【昇腾】LLaMA-Factory 训练 Qwen
@[toc]
服务器:800TA2
1. 使用docker安装 1.1 配置docker 配置docker镜像源:
1 sudo vi /etc/ docker/daemon.json
填入:
1 2 3 4 5 6 7 { "registry-mirrors" : [ "https://2t697950.mirror.aliyuncs.com" , "https://docker.1ms.run" , "https://docker.xuanyuan.me" ] }
安装 docker-compose
1 2 3 sudo curl -L https://gi thub.com/docker/ compose/releases/ download/v2.33.0/ docker-compose-linux-aarch64 -o /usr/ local/bin/ docker-compose chmod 777 /usr/ local/bin/ docker-compose docker-compose -v
1. 2 拉取 LLaMA-Factory 1 2 3 4 5 mkdir /home/aicc1cd /home/aicc1git clone https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory/docker/docker-npu
1.3 修改配置 请保证docker镜像源已配置完毕。Dockerfile 、 docker-compose.yml,中挂载的设备数量、python镜像源。devices挂载了8张卡。
挂载了目录 /home/aicc1,用于与宿主机数据交互。具体请修改为你自己的文件路径
docker-compose.yml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 services: llamafactory: build: dockerfile: ./docker/docker-npu/Dockerfile context: ../.. args: INSTALL_DEEPSPEED: "false" PIP_INDEX: https://pypi.tuna.tsinghua.edu.cn/simple container_name: llamafactory volumes: - ../../hf_cache:/root/.cache/huggingface - ../../ms_cache:/root/.cache/modelscope - ../../om_cache:/root/.cache/openmind - ../../data:/app/data - ../../output:/app/output - /usr/local/dcmi:/usr/local/dcmi - /usr/local/bin/npu-smi:/usr/local/bin/npu-smi - /usr/local/Ascend/driver:/usr/local/Ascend/driver - /etc/ascend_install.info:/etc/ascend_install.info - /home/aicc1:/home/aicc1 - /home/aicc2:/home/aicc2 ports: - "7860:7860" - "8000:8000" ipc: host tty: true shm_size: "16gb" stdin_open: true command: bash devices: - /dev/davinci0 - /dev/davinci1 - /dev/davinci2 - /dev/davinci3 - /dev/davinci4 - /dev/davinci5 - /dev/davinci6 - /dev/davinci7 - /dev/davinci_manager - /dev/devmm_svm - /dev/hisi_hdc restart: unless-stopped
Dockerfile :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 FROM ascendai/cann:8.0 .0 -910 b-ubuntu22.04 -py3.10 ENV DEBIAN_FRONTEND=noninteractiveARG INSTALL_DEEPSPEED=falseARG PIP_INDEX=https://pypi.tuna.tsinghua.edu.cn/simpleARG TORCH_INDEX=https://mirrors.aliyun.com/pytorch-wheels/cpuARG HTTP_PROXY=WORKDIR /app RUN if [ -n "$HTTP_PROXY " ]; then \ echo "Configuring proxy..." ; \ export http_proxy=$HTTP_PROXY ; \ export https_proxy=$HTTP_PROXY ; \ fi COPY requirements.txt /app RUN python -m pip install --upgrade pip && \ pip config set global.index-url "$PIP_INDEX " && \ pip config set global.extra-index-url "$TORCH_INDEX " && \ pip install --retries=3 --timeout =60 \ -r requirements.txt \ -i "$PIP_INDEX " \ --extra-index-url "$TORCH_INDEX " COPY . /app RUN EXTRA_PACKAGES="torch-npu,metrics" ; \ if [ "$INSTALL_DEEPSPEED " == "true" ]; then \ EXTRA_PACKAGES="${EXTRA_PACKAGES} ,deepspeed" ; \ fi ; \ if [ -n "$HTTP_PROXY " ]; then \ pip install --proxy=$HTTP_PROXY -e ".[$EXTRA_PACKAGES ]" ; \ else \ pip install -e ".[$EXTRA_PACKAGES ]" ; \ fi RUN if [ -n "$HTTP_PROXY " ]; then \ unset http_proxy; \ unset https_proxy; \ fi VOLUME [ "/root/.cache/huggingface" , "/root/.cache/modelscope" , "/app/data" , "/app/output" ] ENV GRADIO_SERVER_PORT 7860 EXPOSE 7860 ENV API_PORT 8000 EXPOSE 8000
1.4 构建容器 修改完毕配置后,在路径下:LLaMA-Factory/docker/docker-npu
2. 下载模型 ps:请修改为你要训练的模型
1 2 3 4 5 # 进入容器 docker exec -it llamafactory bash # 下载模型 pip install modelscope modelscope download --model Qwen/Qwen2.5-14B-Instruct --local_dir /home/aicc1/Qwen2.5-14B-Instruct/
3. 准备训练数据 3.1 下载数据集 使用魔搭上一个医疗的数据,大小:580M,格式:Alpaca。传送门
ps:如果认为数据集太大(训练时间会加长),可以下载后删除大部分,保留几百条数据去测试
1 2 3 # 在宿主机上 (容器中没有下载wget) cd /home/aicc1/LLaMA-Factory/data wget https://modelscope.cn/datasets/swift/Alpaca-CoT/resolve/master/Chinese-medical/chinesemedical.json
3.2 自定义数据集配置 如果使用自定义数据集,需要配置LLaMA-Factory
1 vim /home/aicc1/LLaMA-Factory/data/dataset_info.json
在其中添加:
1 2 3 4 5 6 7 8 "my_dataset" : { "file_name" : "chinesemedical.json" , "columns" : { "prompt" : "instruction" , "query" : "input" , "response" : "output" } } ,
4. 训练 4.1 训练配置 1 2 3 mkdir /home/aicc1/LLaMA-Factory/qwen_config cd /home/aicc1/LLaMA-Factory/qwen_config tourch qwen2_5_lora_sft_ds.yaml
qwen2_5_lora_sft_ds.yaml 配置:
该配置采用文档中qwen1.5的训练配置。传送门
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 model_name_or_path: /home/aicc1/Qwen2.5-14B-Instruct stage: sft do_train: true finetuning_type: lora lora_target: q_proj,v_proj ddp_timeout: 180000000 deepspeed: examples/deepspeed/ds_z0_config.json dataset: identity,my_dataset template: qwen cutoff_len: 1024 max_samples: 1000 overwrite_cache: true preprocessing_num_workers: 16 output_dir: saves/Qwen2.5-14B/lora/sft logging_steps: 10 save_steps: 500 plot_loss: true overwrite_output_dir: true per_device_train_batch_size: 1 gradient_accumulation_steps: 2 learning_rate: 0.0001 num_train_epochs: 10.0 lr_scheduler_type: cosine warmup_ratio: 0.1 fp16: true val_size: 0.1 per_device_eval_batch_size: 1 eval_strategy: steps eval_steps: 500
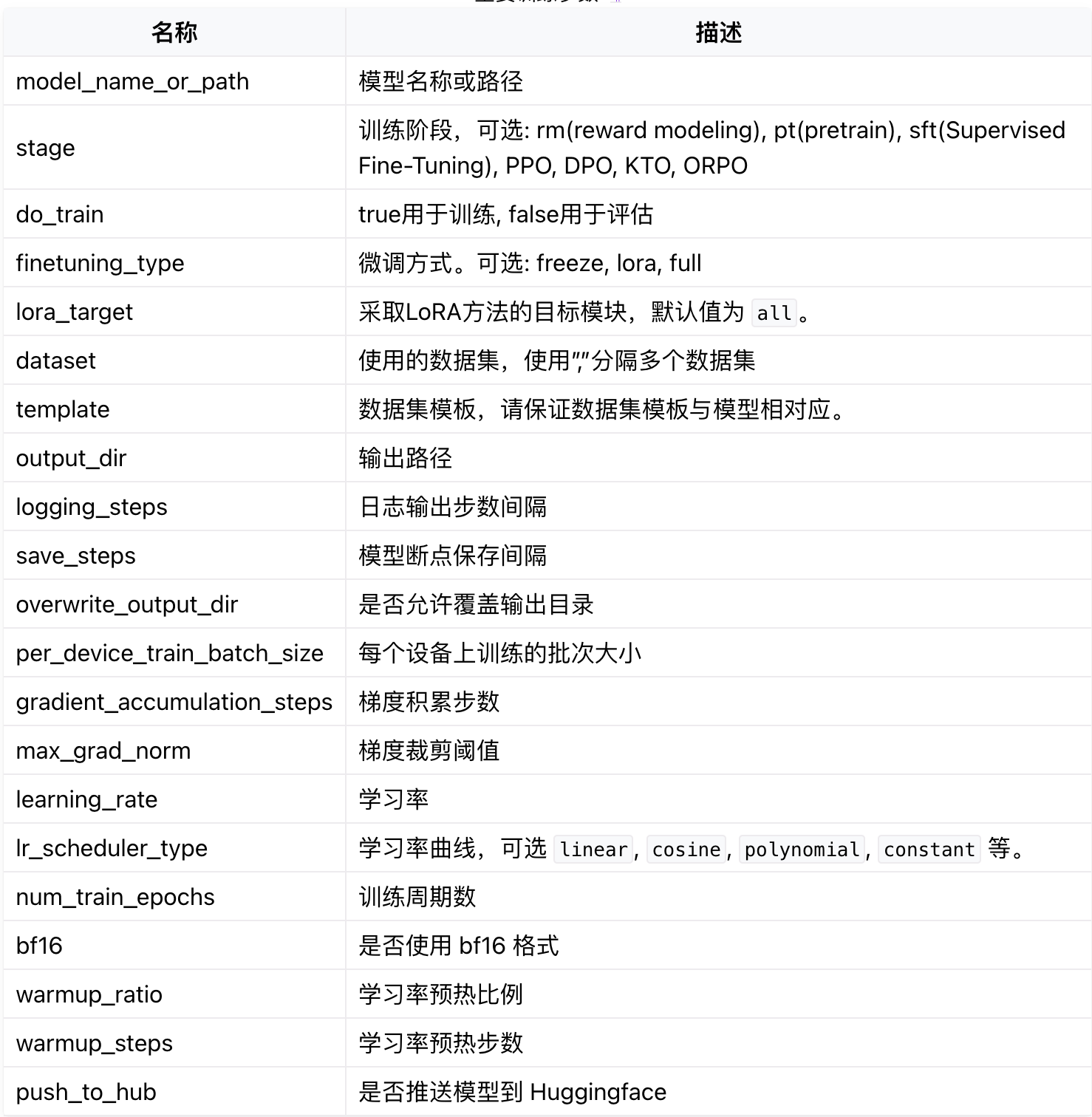
请注意一些关键参数:
本篇用到的数据集为 LLaMA-Factory 自带的 identity 和 自定义的my_dataset,对 identity 数据集进行如下全局替换即可实现定制指令:
替换为 Ascend-helper
替换为 Ascend
执行下方命令替换:
1 sed -i 's/{{name}}/Ascend-helper/g; s/{{author}}/Ascend/g' /home/aicc1/LLaMA-Factorydata/identity.json
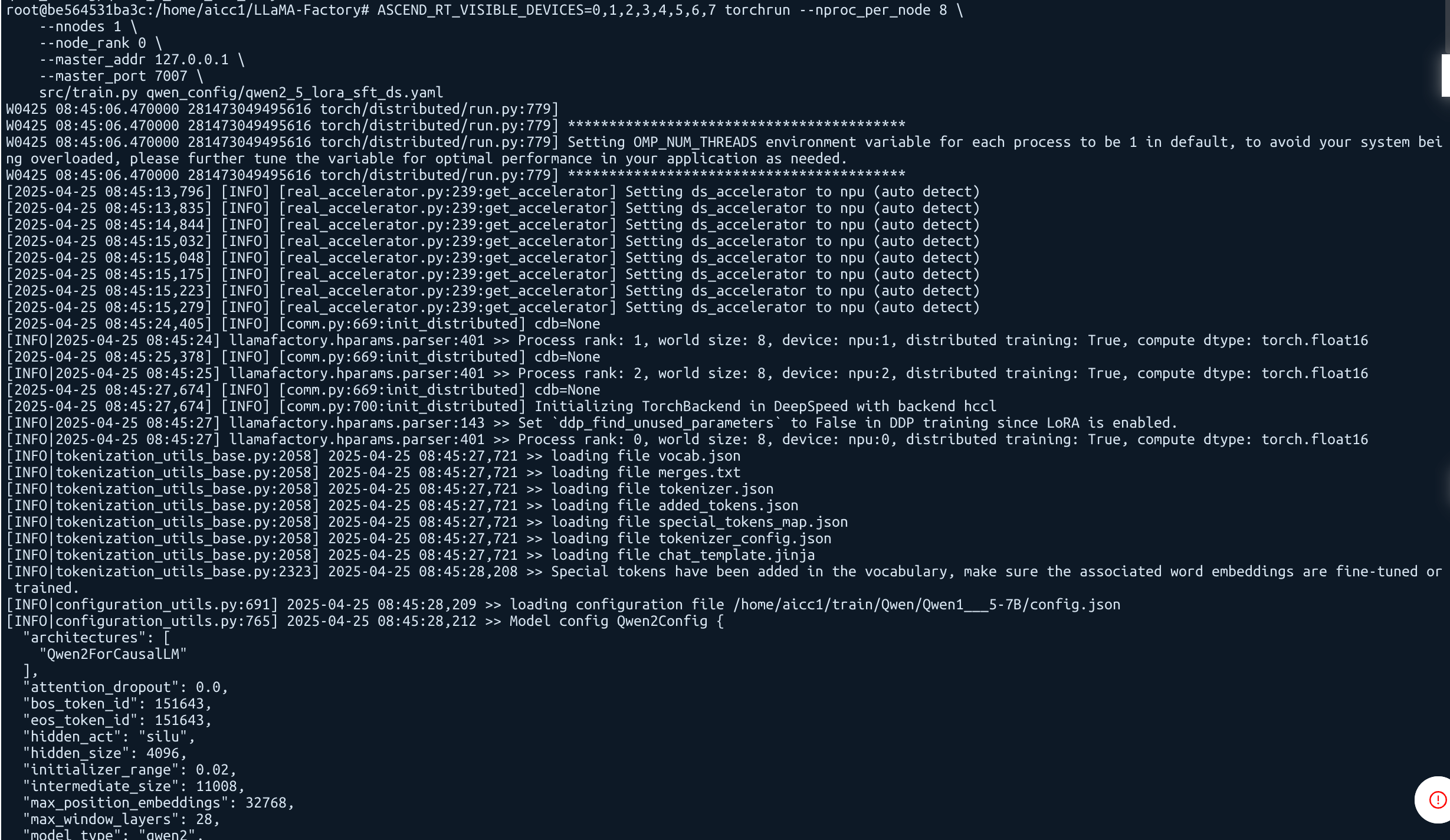
4.2 启动训练 1 2 3 4 5 6 7 cd /home/aicc1/LLaMA-Factory ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node 8 \ --nnodes 1 \ --node_rank 0 \ --master_addr 127.0.0.1 \ --master_port 7007 \ src/train.py qwen_config/qwen2_5_lora_sft_ds.yaml
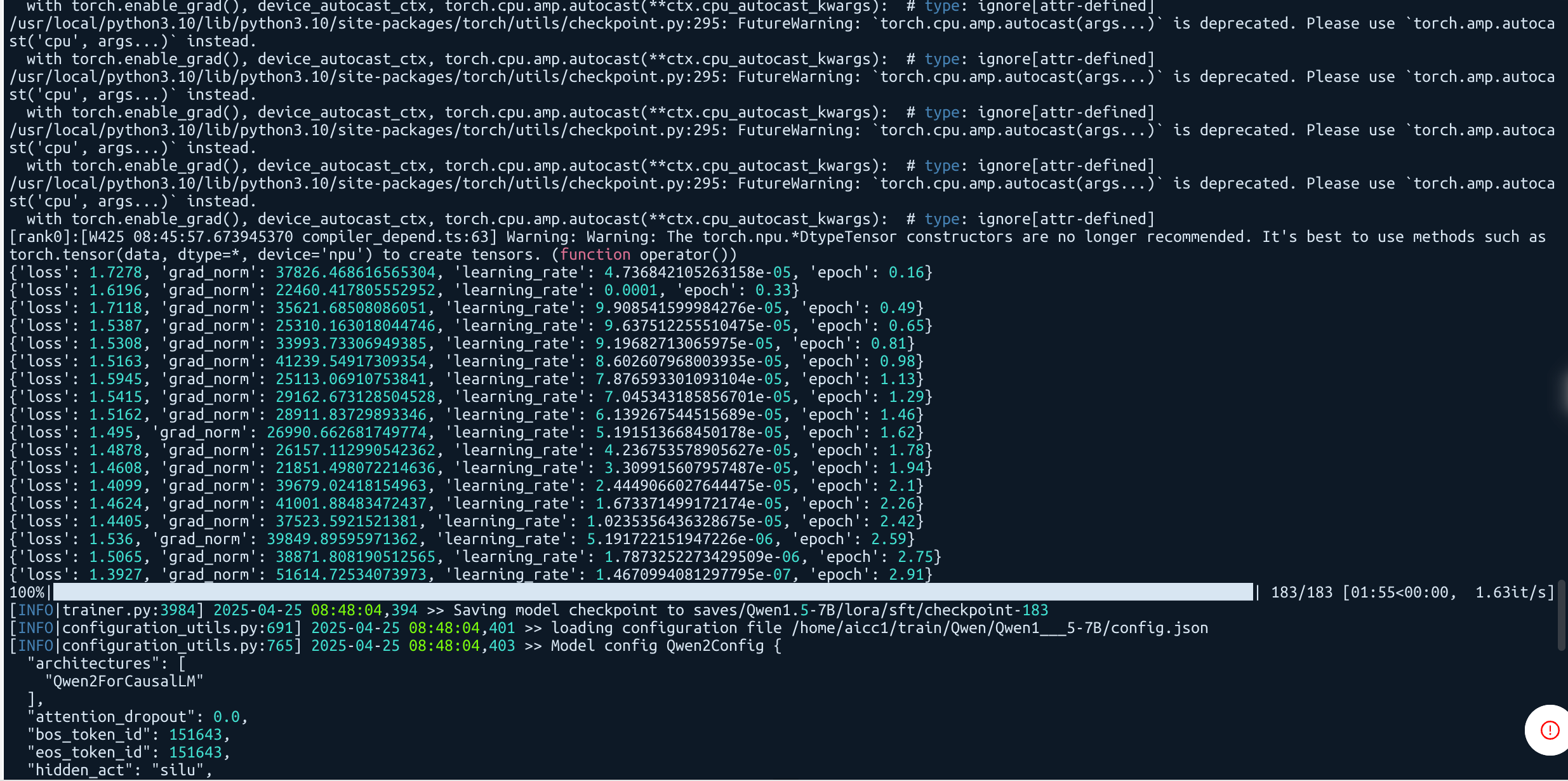
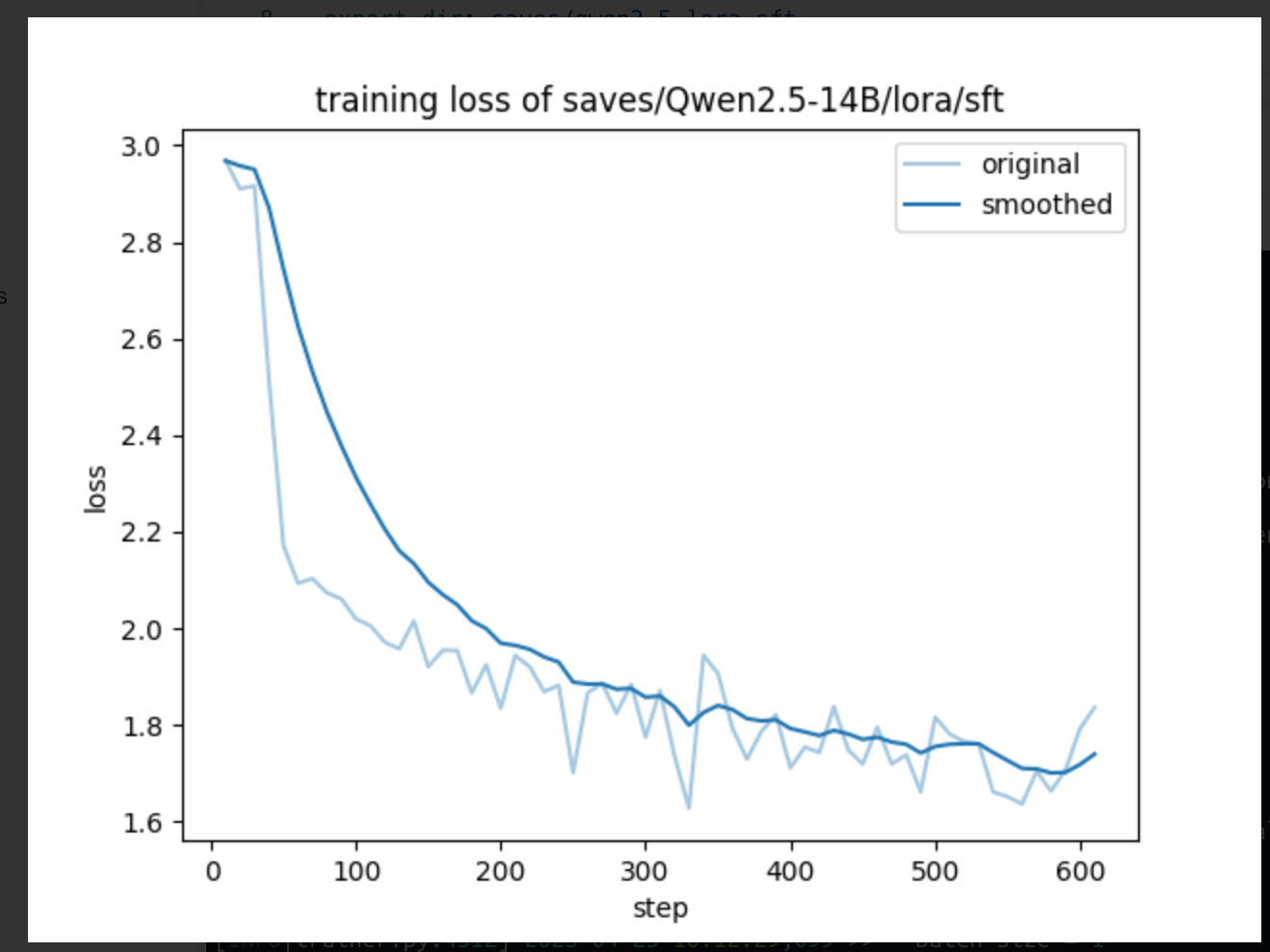
训练开始: 训练中间: 训练结束:
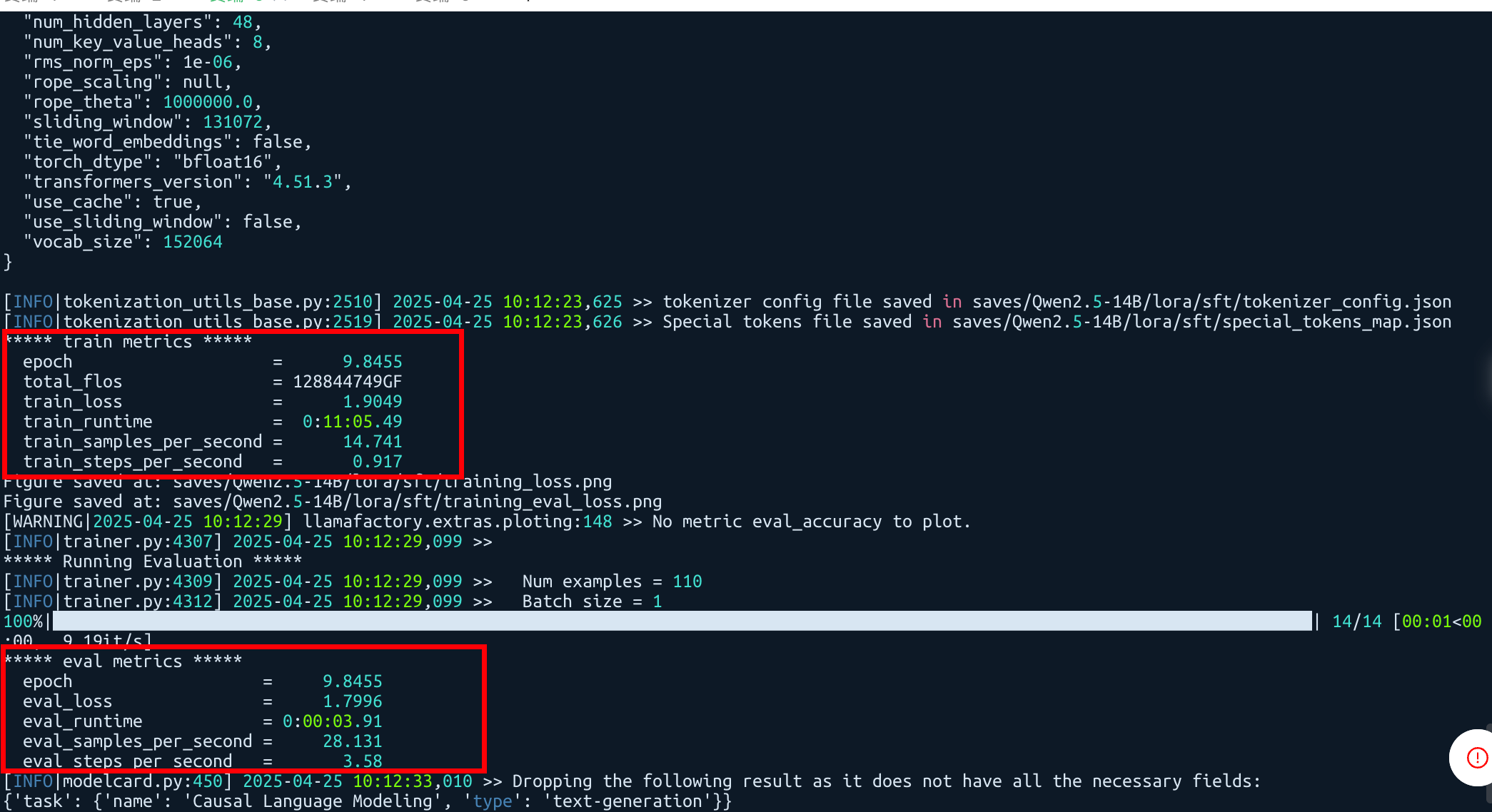
输出关于训练、评估的指标信息
4.3 训练效果测试 指定原始模型路径、训练后lora路径。
1 2 3 4 llamafactory-cli chat --model_name_or_path /home/aicc1/Qwen2.5-14B-Instruct \ --adapter_name_or_path /home/aicc1/LLaMA-Factory/saves/Qwen2.5-14B/lora/sft \ --template qwen \ --finetuning_type lora
询问identity数据集内容,返回成功。如图所示:
5. 合并权重 1 2 3 4 5 6 7 8 9 ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 llamafactory-cli export \ --model_name_or_path /home/aicc1/Qwen2.5-14B-Instruct \ --adapter_name_or_path ./saves/Qwen2.5-14B/lora/sft \ --template qwen \ --finetuning_type lora \ --export_dir ./saves/Qwen2.5-14B/lora/megred-model-path \ --export_size 2 \ --export_device auto \ --export_legacy_format False